
HDFS
Hdfs用户权限问题
打开Hdfs和yarn的UI在Kerberos的环境下
在hdfs的配置中搜索http
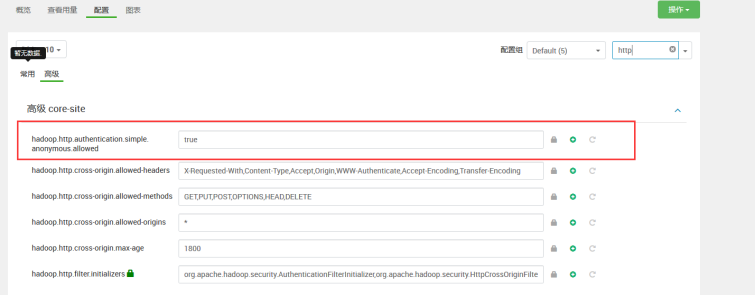
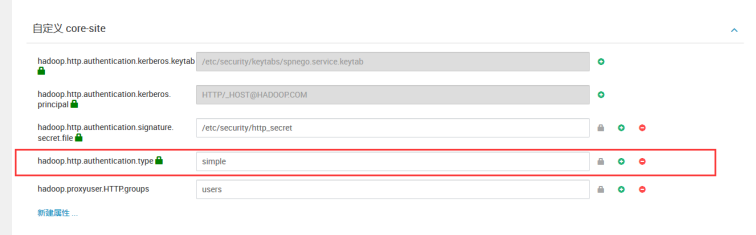
在yarn的高级配置中搜索http
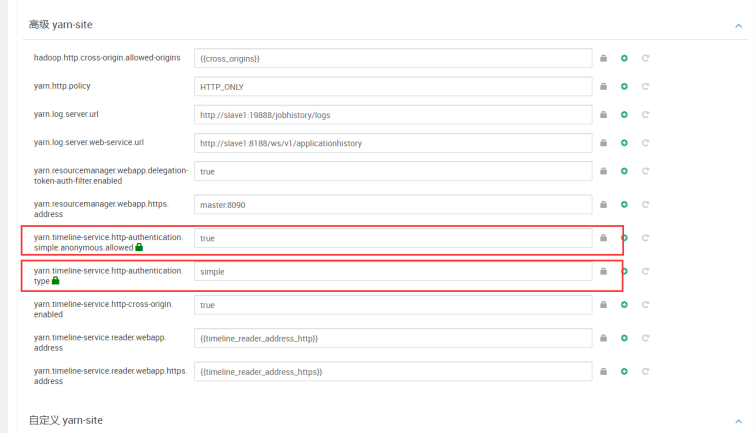
重启hdfs、yarn
namenode启动报错在日志文件中ERROR namenode.NameNode (NameNode.java:main(1712)) - Failed to start namenode
原因:日志中还有java.net.BindException: Port in use: gmaster:50070,Caused by: java.net.BindException: Address already in use
判断原因是50070上一次没有释放,端口占用
解决:
netstat下time_wait状态的tcp连接:
1.这是一种处于连接完全关闭状态前的状态;
2.通常要等上4分钟(windows server)的时间才能完全关闭;
3.这种状态下的tcp连接占用句柄与端口等资源,服务器也要为维护这些连接状态消耗资源;
4.解决这种time_wait的tcp连接只有让服务器能够快速回收和重用那些TIME_WAIT的资源:修改注册表 [HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\services\Tcpip\Parameters]添加dword值TcpTimedWaitDelay=30(30也为微软建议值;默认为2分钟)和MaxUserPort:65534(可选值5000 - 65534);
5.具体tcpip连接参数配置还可参照这里: http://technet.microsoft.com/zh-tw/library/cc776295%28v=ws.10%29.aspx
6.linux下:
vi /etc/sysctl.conf
新增如下内容:
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_syncookies=1
net.ipv4.tcp_fin_timeout=30
net.ipv4.tcp_keepalive_time=1800
net.ipv4.tcp_max_syn_backlog=8192
使内核参数生效:
[root@web02 ~]# sysctl -p
readme:
net.ipv4.tcp_syncookies=1 打开TIME-WAIT套接字重用功能,对于存在大量连接的Web服务器非常有效。
net.ipv4.tcp_tw_recyle=1
net.ipv4.tcp_tw_reuse=1 减少处于FIN-WAIT-2连接状态的时间,使系统可以处理更多的连接。
net.ipv4.tcp_fin_timeout=30 减少TCP KeepAlive连接侦测的时间,使系统可以处理更多的连接。
net.ipv4.tcp_keepalive_time=1800 增加TCP SYN队列长度,使系统可以处理更多的并发连接。
net.ipv4.tcp_max_syn_backlog=8192
Cannot set permission for /ats/done. Name node is in safe mode.
使用hdfs用户执行以下命令,让NameNode处于非安全模式即可。
$ sudo -u hdfs Hadoop dfsadmin -safemode leave
HDFS块丢失异常
现象:
HDFS进入安全模式,服务不可用。
HDFS服务页面块丢失的值大于0。
HDFS服务启动失败,角色实例启动成功。
可能原因:
数据节点硬盘故障,或节点故障可能导致数据副本丢失。
HDFS在如下情况进入安全模式:
当NameNode启动且等待DataNode上报副本。
NameNode所在磁盘空间不足。
恢复NameNode数据后,元数据与业务数据无法匹配
HDFS对应文件的副本全部丢失。
解决:
打开托管HADOOP的管理界面,看是否有节点、硬盘故障告警。
以“hdfs”用户使用HDFS客户端工具执行fsck检查文件系统中文件是否完整。
若fsck校验仅显示副本丢失,而不是文件丢失(看已有副本数是否大于0),则执行hdfs dfsadmin -safemode leave退出HDFS安全模式,即可修复。
若文件丢失,检查是否执行了恢复NameNode数据操作。
是,表示找不到与元数据对应的业务数据块,执行hdfs dfsadmin -safemode leave退出HDFS安全模式
否,表示文件丢失
若有文件丢失,检查丢失文件的文件路径,并检查文件是否为重要文件。
MapReduce类文件是非重要的,对非重要文件,退出安全模式后,可执行删除操作。
hdfs fsck [path-to-file] -delete
恢复NameNode数据后可能导致元数据与业务数据无法匹配,需要执行删除操作。
hdfs fsck / -delete
检查NameNode的块丢失阈值是否配置过高。
重启HDFS服务。
HDFS客户端无法连接到HDFS集群
现象:
HDFS客户端无法连接到HDFS。
原因:
未通过Kerberos安全认证。
NameNode IP地址不正确。
HDFS服务不正常。
解决:
服务列表界面及告警界面检查HDFS服务是否正常
查看正确的ip地址。
如果集群为安全模式,执行命令kinit hdfs,以业务帐户登录HDFS客户端。
Hive
hive3.0 current_timestamp时间差问题
Hive3.0时间戳默认时区是UTC,currenttimestamp是从UTC取时间,不是从本地获取。所以要获取当前系统时间使用函数 fromutctimestamp(currenttimestamp,’Asia/Shanghai’)。
hive中文注释乱码问题
原因:Hive字段中文乱码,如执行 show create table xxx 时,表级别注释、字段级别注释发现有乱码现象,一般都是由hive 元数据库的配置不当造成的。
解决:登录hive的元数据库mysql中:
设置hive 元数据库字符集
show create database hive;
查看为utf8,需变更为latin1
alter database hive character set latin1;
更改如下表字段为字符集编码为 utf8
hive权限管理、ranger权限管理、hdfs权限管理,hive权限
通过ranger管理,可跳过hdfs文件权限
在使用hive命令进入hive的时候报错误Permission denied: user=root, access=WRITE, inode="/user/root":hdfs:hdfs:drwxr-xr-x hive
在有ranger的情况下使用ranger赋权
在没有ranger的情况下:
使用HDFS的命令行接口修改相应目录的权限,Hadoop fs -chmod 777 /user,后面的/user是要上传文件的路径,不同的情况可能不一样,比如要上传的文件路径为hdfs://namenode/user/xxx.doc,则这样的修改可以,如果要上传的文件路径为 hdfs://namenode/java/xxx.doc,则要修改的为Hadoop fs -chmod 777 /java或者Hadoop fs -chmod 777 /,java的那个需要先在HDFS里面建立Java目录,后面的这个是为根目录调整权限。
脚本 :
su - hdfs
Hadoop fs -chmod 777 /user
在/etc/profile文件中加上系统的环境变量或java JVM变量里面添加export HADOOP_USER_NAME=hdfs(ambari使用的Hadoop用户是hdfs),这个值具体等于多少看自己的情况,以后会运行HADOOP上的Linux的用户名。
export HADOOP_USER_NAME=hdfs
Shell客户端提示“authentication failed”
现象:
安全版本的集群中,HiveServer服务正常的情况下,Shell客户端中执行beeline命令,登录失败,界面提示“authentication failed”关键字
原因:
客户端用户未进行Kerberos认证。
Kerberos认证超期
解决:
对客户端用户再次进行Kerberos认证
认证完成后,再次登录。
恢复该故障正常设置耗时1分钟以内。
操作表时Shell客户端提示“Unable to determine if xxx encryptede”
现象:
在HiveServer服务正常的情况下,用户poctest去访问表checkpoint,命令行终端显示类似如下错误:
0: jdbc:hive2://ha-cluster/default> select * from checkpoint;
Error: Error while compiling statement: FAILED: SemanticException Unable to determine if hdfs://hacluster/user/hive/warehouse/checkpointis encrypted: org.apache.Hadoop.security.AccessControlException: Permission denied: user=poctest, access=READ, inode="/user/hive/warehouse/checkpoint":pocown:hive:drwx------
原因: 如果没有给poctest用户授予checkpoint表的访问权限,用户无法访问该表。 解决: 查看poctest用户权限是否有checkpoint表的访问权限。 使用Ranger界面授权授予poctest用户checkpoint表的访问权限。 正常授权耗时1分钟以内。 Hive服务器端日志显示“File does not exist”异常 现象: 在HiveServer服务正常的情况下,开启Hive本地模式,对HiveoverHBase表(数据存于HBase的表)进行操作(如查询),Hive客户端显示执行错误,同时Hive服务器端的子进程日志显示“File does not exist”异常。 Hive客户端执行错误,具体信息如下:
0: jdbc:hive2://10.64.35.144:21066/default> select count(*) from default__tb_1_index_3__;
Error: Error while processing statement: FAILED: Execution Error, return code 1 from org.apache.Hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=1)
查询“/var/log/Bigdata/hive/hiveserver/hive.log”路径下的Hive服务器端的子进程日志显示“File does not exist”异常,具体信息如下:
2015-03-30 14:17:34,586 ERROR [main]: mr.ExecDriver (SessionState.java:printError(548)) - Job Submission failed with exception 'java.io.FileNotFoundException(File does not exist: hdfs://hacluster/opt/huawei/Bigdata/FusionInsight_HD_V100R002CXX/install/FusionInsight-Hive-1.3.0/hive-1.3.0/lib/hive-hbase-handler-1.3.0.jar)'
java.io.FileNotFoundException: File does not exist: hdfs://hacluster/opt/huawei/Bigdata/FusionInsight_HD_V100R002CXX/install/FusionInsight-Hive-1.3.0/hive-1.3.0/lib/hive-hbase-handler-1.3.0.jar
原因:
在集群模式下,运行MapReduce作业时,第三方jar包放置在分布式缓存中,作业运行完后jar包释放。在本地模式(Local Mode)下,需要从本机中获取第三方jar包,但现有的MapReduce机制不支持从本机获取第三方jar包。在Hive提交作业后,MapReduce会把第三方jar包的路径强制转换为本地模式下不存在的HDFS路径,导致系统运行作业时取不到jar包而出错。
例如,第三方jar包路径为“file:/opt/huawei/BigData/hive/lib/hbase-exec.jar”。运行MapReduce作业前,系统会强制将该路径转化为不存在的路径“hdfs:/opt/huawei/BigData/hive/lib/hbase-exec.jar”。
解决:
在进行HiveoverHBase表操作之前,上传第三方jar包到HDFS的指定路径,可解决该问题。
通过Hue界面执行SQL失败时页面没有提示信息
现象:
通过Hue界面的“Query Editor > Hive”页面,执行SQL语句。因为语句原因或者权限问题导致语句执行失败,但是页面没有错误信息提示。
如下图所示: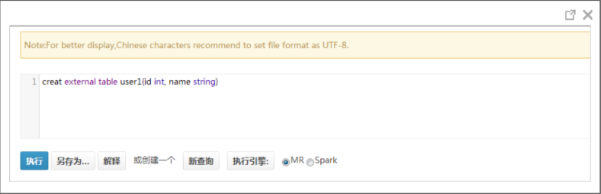
正常情况下应该有如下提示信息: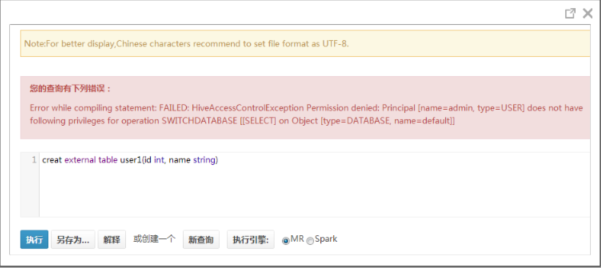
原因:
可能是浏览器缓存导致信息无法正常显示。
极少数情况会出现错误信息无法提示的情况。
解决:
清除浏览器缓存即可解除此问题。
执行动态插入分区时,在MapReduce日志中报 “java.lang.OutOfMemoryError: GC overhead limit exceeded”错误
现象:
在HiveServer服务正常的情况下,执行动态插入分区时,在MapReduce日志报“java.lang.OutOfMemoryError: GC overhead limit exceeded”错误。
原因:
产生OOM的原因是单个任务处理的分区数过多,需要针对具体场景,减少单个task处理的分区数。
解决:
参照如下样例进行操作。
样例建表语句如下:
create table test(id int )partitioned by (dt int);
create table test1(id int, dt int);
正常的动态插入分区语句为:
insert overwrite table test partition (dt) select id, dt from test;
HBase
HMaster Web UI显示空region,重新创建相同的table时失败
现象:
HMaster Web UI可能显示空region的table。
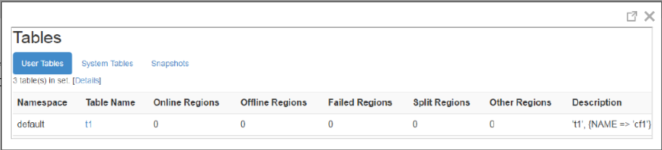
当客户端重试创建相同的table时会上报下面的错误。
ERROR: java.io.IOException: the table directory:hdfs://10.18.106.212:8020/hbase/data/default/t1 exists,this may be created by other process,please delete the directory first.
at org.apache.Hadoop.hbase.master.handler.CreateTableHandler.prepare(CreateTableHandler.java:131)
at org.apache.Hadoop.hbase.master.HMaster.createTable(HMaster.java:1559)
at org.apache.Hadoop.hbase.master.MasterRpcServices.createTable(MasterRpcServices.java:468)
at org.apache.Hadoop.hbase.protobuf.generated.MasterProtos$MasterService$2.callBlockingMethod(MasterProtos.java:59779)
at org.apache.Hadoop.hbase.ipc.RpcServer.call(RpcServer.java:2171)
at org.apache.Hadoop.hbase.ipc.CallRunner.run(CallRunner.java:112)
at org.apache.Hadoop.hbase.ipc.RpcExecutor.consumerLoop(RpcExecutor.java:133)
at org.apache.Hadoop.hbase.ipc.RpcExecutor$1.run(RpcExecutor.java:108)
at java.lang.Thread.run(Thread.java:745)
原因:
在故障情况下,当HMaster在文件系统中已经创建了table,但是由于一些原因在meta table中不能更新region信息。所以table在文件系统中存在但是在meta table中不存在。
在HMaster主备倒换/重启时,HMaster Web UI将会显示如上图所示的空region。这里的table是基于文件系统而不是meta table列出的,所以hbase中不存在表的region信息,meta table显示为空。
解决:
扫描“hbase:meta”table,并检查是否存在table region信息。
Could not create the Java Virtual Machine.
现象:
执行$ hbase hbck 命令时,出现以下提示:
Invalid maximum heap size: -Xmx4096m
The specified size exceeds the maximum representable size.
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
原因:
jvm设置的内存过大。
解决:
减小配置文件hbase-env.sh内的设置即可。
export HBASE_HEAPSIZE=1024
无法启动hbase,regionserver log里会有这样的错误,zookeeper也有初始化问题的错误
现象:
FATAL org.apache.Hadoop.hbase.regionserver.HRegionServer: ABORTING region server 10.210.70.57,60020,1340088145399: Initialization of RS failed. Hence aborting RS.
解决:
因为之前安装配置的时候是好好的,中间经历过强行kill daemon的过程,又是报错初始化问题,所以估计是有缓存影响了,所以清理了tmp里的数据,然后发现HRegionServer依然无法启动,不过还好的是zookeeper启动了,一怒之下把hdfs里的hbase数据也都清理了,同时再清理tmp,检查各个节点是否有残留hbase进程,kill掉,重启hbase,然后这个世界都正常了。不知道具体哪里影响了,不推荐这种暴力解决办法,如果有谁知道原因请告之
无法启动reginserver daemon
现象:
Exception in thread "main" java.lang.RuntimeException: Failed construction of Regionserver: class org.apache.Hadoop.hbase.regionserver.HRegionServer
...
Caused by: java.net.BindException: Problem binding to /10.210.70.57:60020 : Cannot assign requested address
解决:
根据错误提示,检查ip对应的机器是否正确,如果出错机器的ip正确,检查60020端口是否被占用。
regionserver无法启动
现象:
如果启动hbase集群出现regionserver无法启动,日志报告如下类似错误时,说明是集群的时间不同步,只需要同步即可解决。
FATAL org.apache.Hadoop.hbase.regionserver.HRegionServer: ABORTING region server 10.210.78.22,60020,1344329095415: Unhandled exceptio
n: org.apache.Hadoop.hbase.ClockOutOfSyncException: Server 10.210.78.22,60020,1344329095415 has been rejected; Reported time is too far out of sync with mast
er. Time difference of 90358ms > max allowed of 30000ms
org.apache.Hadoop.hbase.ClockOutOfSyncException: org.apache.Hadoop.hbase.ClockOutOfSyncException: Server 10.210.78.22,60020,1344329095415 has been rejected;
Reported time is too far out of sync with master. Time difference of 90358ms > max allowed of 30000ms
......
Caused by: org.apache.Hadoop.ipc.RemoteException: org.apache.Hadoop.hbase.ClockOutOfSyncException: Server 10.210.78.22,60020,1344329095415 has been rejected;
Reported time is too far out of sync with master. Time difference of 90358ms > max allowed of 30000ms
解决:
只需要执行一下这条命令即可同步国际时间:
/usr/sbin/ntpdate tick.ucla.edu tock.gpsclock.com ntp.nasa.gov timekeeper.isi.edu usno.pa-x.dec.com;/sbin/hwclock --systohc > /dev/null
Failed all from refion=r
现象:
 原因:
因为服务器处理时间过长,客户端自动断开连接,当服务器处理完成返回数据时,发现连接断开,故抛出异常。
解决:
hbase.rpc.timeout默认值为60000ms,可以适当调大这个值,可以从配置文件里调整,也可以通过conf.set("hbase.rpc.timeout", "6000000")进行调整。
将zookeeper的时间调大:调整zookeeper.session.timeout在hbase-site.xml中调大如下两个值(根据实际情况调大)
原因:
因为服务器处理时间过长,客户端自动断开连接,当服务器处理完成返回数据时,发现连接断开,故抛出异常。
解决:
hbase.rpc.timeout默认值为60000ms,可以适当调大这个值,可以从配置文件里调整,也可以通过conf.set("hbase.rpc.timeout", "6000000")进行调整。
将zookeeper的时间调大:调整zookeeper.session.timeout在hbase-site.xml中调大如下两个值(根据实际情况调大)
<property>
<name>zookeeper.session.timeout</name>
<value>60000</value>
</property>
<property>
<name>hbase.zookeeper.property.tickTime</name>
<value>2000</value>
</property>
加大region数据,让region均匀分配:调节hbase-site.xml中的hbase.hregion.max.filesize值,默认为256M,可以调整到1G,有人甚至调到4G(更大的Region可以使你集群上的Region的总数量较少。一般来言,更少的Region可以使你的集群运行更加流畅。)。
Kafka
kafka的消费和生产在添加kerberos都出现问题
现象:
WARN [Producer clientId=console-producer] Bootstrap broker 托管Hadoop-master1:6667 (id: -1 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[root@托管Hadoop-master1 kafka]# ./bin/kafka-console-producer.sh --broker-list 托管Hadoop-master1:6667 --topic test1
[root@托管Hadoop-master1 kafka]# bin/kafka-console-consumer.sh
--bootstrap-server 托管Hadoop-master1:6667 --topic first1111

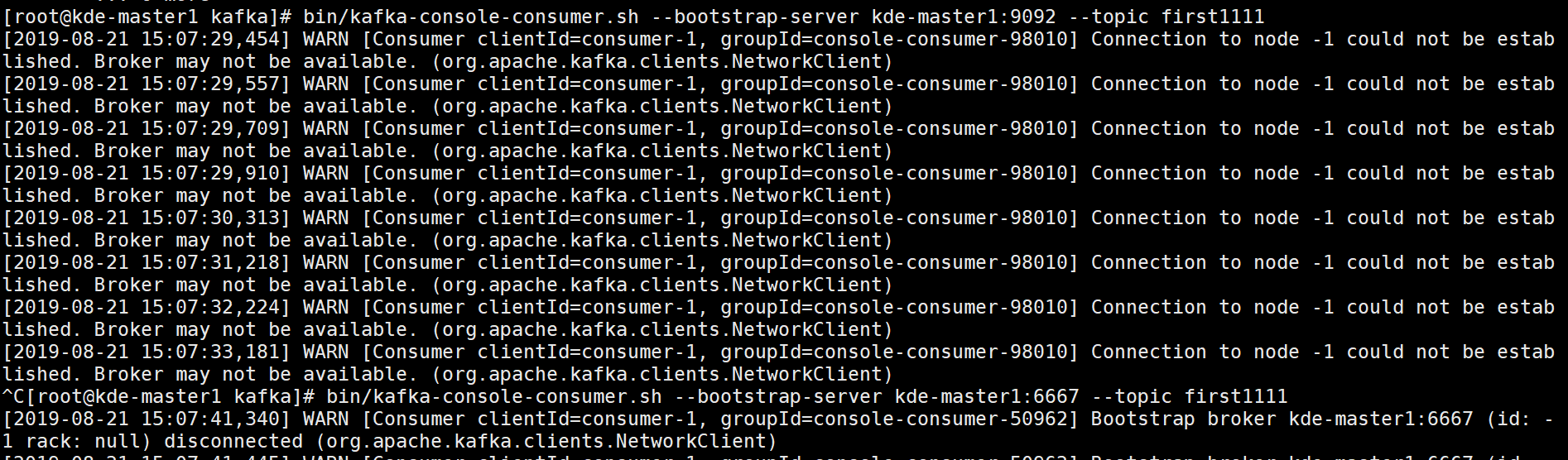
解决:
在命令的最后添加--security-protocol PLNTEXTSASL
[root@托管Hadoop-master1 kafka]# ./bin/kafka-console-producer.sh --broker-list 托管Hadoop-master1:6667 --topic first1111 --security-protocol PLAINTEXTSASL
[root@托管Hadoop-master1 kafka]# bin/kafka-console-consumer.sh --bootstrap-server 托管Hadoop-master1:6667 --topic first1111 --security-protocol PLNTEXTSASL
找不到zk的元数据
现象:
WARN [Producer clientId=console-producer] Error while fetching metadata with correlation id 1 : {first111=LEADERNOTAVAILABLE} (org.apache.kafka.clients.NetworkClient)
 原因:
zk的地址出现了问题,可能是原数据里面有脏数据或者数据损坏,在zk的元数据连接后面重新添加一个目录
解决:
原因:
zk的地址出现了问题,可能是原数据里面有脏数据或者数据损坏,在zk的元数据连接后面重新添加一个目录
解决:
 Kafka节点磁盘占用率达到100%后导致Broker实例状态为“恢复中”
现象:
当Kafka配置的数据目录所在的磁盘占用率达到100%后,该节点的Broker实例出现“恢复中”状态,导致当前节点无法提供Kafka服务。
原因:
Topic的Partition划分不合理,导致个别磁盘占用率达到100%。
本地磁盘上还存在除Kafka外的其他数据,导致磁盘占用率达到100%。
解决:
定位磁盘占用率达到100%的根因。
删除或移动数据到其他空闲磁盘,重启Broker。
解决磁盘容量不足问题
Yarn
NodeManager节点故障
现象:
一个或者多个NodeManager处于“恢复中”状态。
上报NodeManager不健康告警或者NodeManager心跳丢失告警。
当MapReduce任务进行过程中,出现NodeManager节点故障,可能会导致任务失败或者运行速度变慢。
原因:
该节点网络异常。
ZooKeeper服务异常。
该节点NodeManager进程异常。
解决:
查看ZooKeeper服务是否正常。
查看ResourceManager页面中提供的异常信息。
NodeManager出现内存超限错误导致执行Spark任务失败
现象:
当开启Spark动态调度时,运行大数据量(百万task)的Spark任务,在执行到reduce阶段时出现重试,多次重试后任务执行失败。运行过程中,NodeManager进程出现“java.lang.OutOfMemoryError: Direct buffer memory”的错误,日志如下:
Kafka节点磁盘占用率达到100%后导致Broker实例状态为“恢复中”
现象:
当Kafka配置的数据目录所在的磁盘占用率达到100%后,该节点的Broker实例出现“恢复中”状态,导致当前节点无法提供Kafka服务。
原因:
Topic的Partition划分不合理,导致个别磁盘占用率达到100%。
本地磁盘上还存在除Kafka外的其他数据,导致磁盘占用率达到100%。
解决:
定位磁盘占用率达到100%的根因。
删除或移动数据到其他空闲磁盘,重启Broker。
解决磁盘容量不足问题
Yarn
NodeManager节点故障
现象:
一个或者多个NodeManager处于“恢复中”状态。
上报NodeManager不健康告警或者NodeManager心跳丢失告警。
当MapReduce任务进行过程中,出现NodeManager节点故障,可能会导致任务失败或者运行速度变慢。
原因:
该节点网络异常。
ZooKeeper服务异常。
该节点NodeManager进程异常。
解决:
查看ZooKeeper服务是否正常。
查看ResourceManager页面中提供的异常信息。
NodeManager出现内存超限错误导致执行Spark任务失败
现象:
当开启Spark动态调度时,运行大数据量(百万task)的Spark任务,在执行到reduce阶段时出现重试,多次重试后任务执行失败。运行过程中,NodeManager进程出现“java.lang.OutOfMemoryError: Direct buffer memory”的错误,日志如下:
2019-07-06 19:05:15,794 | WARN | shuffle-server-37 | Exception in connection from /172.16.0.130:49654 | TransportChannelHandler.java:79
io.netty.handler.codec.DecoderException: java.lang.OutOfMemoryError: Direct buffer memory
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:153)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:333)
at io.netty.channel.AbstractChannelHandlerContext.fireChannelRead(AbstractChannelHandlerContext.java:319)
at io.netty.channel.DefaultChannelPipeline.fireChannelRead(DefaultChannelPipeline.java:787)
at io.netty.channel.nio.AbstractNioByteChannel$NioByteUnsafe.read(AbstractNioByteChannel.java:130)
at io.netty.channel.nio.NioEventLoop.processSelectedKey(NioEventLoop.java:511)
at io.netty.channel.nio.NioEventLoop.processSelectedKeysOptimized(NioEventLoop.java:468)
at io.netty.channel.nio.NioEventLoop.processSelectedKeys(NioEventLoop.java:382)
at io.netty.channel.nio.NioEventLoop.run(NioEventLoop.java:354)
at io.netty.util.concurrent.SingleThreadEventExecutor$2.run(SingleThreadEventExecutor.java:116)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Direct buffer memory
at java.nio.Bits.reserveMemory(Bits.java:693)
at java.nio.DirectByteBuffer.<init>(DirectByteBuffer.java:123)
at java.nio.ByteBuffer.allocateDirect(ByteBuffer.java:311)
at io.netty.buffer.PoolArena$DirectArena.newChunk(PoolArena.java:434)
at io.netty.buffer.PoolArena.allocateNormal(PoolArena.java:179)
at io.netty.buffer.PoolArena.allocate(PoolArena.java:168)
at io.netty.buffer.PoolArena.reallocate(PoolArena.java:277)
at io.netty.buffer.PooledByteBuf.capacity(PooledByteBuf.java:108)
at io.netty.buffer.AbstractByteBuf.ensureWritable(AbstractByteBuf.java:251)
at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:849)
at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:841)
at io.netty.buffer.AbstractByteBuf.writeBytes(AbstractByteBuf.java:831)
at io.netty.handler.codec.ByteToMessageDecoder.channelRead(ByteToMessageDecoder.java:146)
原因:
当开启Spark动态调度特性时,NodeManager处理spark shuffle数据需要大量的内存,如果NodeManager相关的内存参数配置的不够大,便会出现“java.lang.OutOfMemoryError: Direct buffer memory”的错误。
解决:
查看NodeManager的日志,看是否存在错误日志“OutOfMemoryError”。
不能提交任务
现象:
Hadoop jar /usr/hdp/current/Hadoop-mapreduce-client/Hadoop-mapreduce-examples.jar pi -Dmapred.job.queue.name=default 10 100
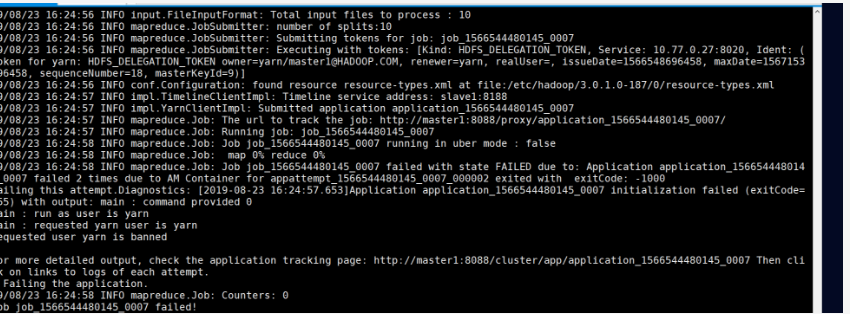 解决:
不用yarn用户提交任务
找不到或无法加载主类
现象:
找不到或无法加载主类 org.apache.Hadoop.mapreduce.v2.app.MRAppMaster
解决:
不用yarn用户提交任务
找不到或无法加载主类
现象:
找不到或无法加载主类 org.apache.Hadoop.mapreduce.v2.app.MRAppMaster
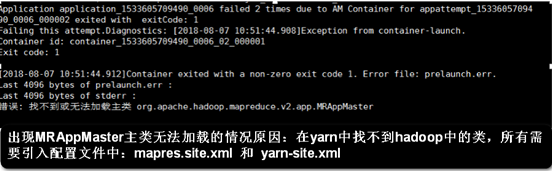 解决:
在mapred-site.xml 和 yarn-site.xml添加如下
解决:
在mapred-site.xml 和 yarn-site.xml添加如下
<property>
<name>yarn.application.classpath</name>
<value>
/opt/Hadoop-2.6.0/etc/Hadoop,
/opt/Hadoop-2.6.0/share/Hadoop/common/*,
/opt/Hadoop-2.6.0/share/Hadoop/common/lib/*,
/opt/Hadoop-2.6.0/share/Hadoop/hdfs/*,
/opt/Hadoop-2.6.0/share/Hadoop/hdfs/lib/*,
/opt/Hadoop-2.6.0/share/Hadoop/mapreduce/*,
/opt/Hadoop-2.6.0/share/Hadoop/mapreduce/lib/*,
/opt/Hadoop-2.6.0/share/Hadoop/yarn/*,
/opt/Hadoop-2.6.0/share/Hadoop/yarn/lib/*
</value>
</property>
ZooKeeper session失效 现象: session失效,导致注册的watcher全部丢失。 原因: 如果zookeeper client与server在协商的超时时间内仍没有建立连接,当client与server再次建立连接时,由于session失效了,所有watcher已经被服务器端删除,从而导致所有的watcher需要重新注册。 session 失效,zookeeper client与server重连后所有watcher都会收到两次触发,第一次 wathetr state = 1,type = -1(state = 1表示正在连接中,type = -1 表示session事件);第二次 watcher state = -112,type = -1(state = -112表示session失效)。 解决: 可以通过以下两种方法解决session失效问题 获取触发session失效watcher后,业务重新注册所有的watcher。 不能根本解决,但是可以减小session失效的概率。通过zookeeper client 与server设置更长的session超时时间。 zookeeperinit设置recvtimeout较长却没有效果 现象: zookeeperinit设置recvtimeout 100000ms,但客户端与服务端断开连接30s就session失效了。 原因: 关于session超时时间的确定:zookeeperinit中设置的超时时间并非真正的session超时时间,session超时时间需要 server与client协商,业务通过zoorecvtimeout(zhandlet* zh)获取server与client协商后的超时时间。服务端: minSessionTimeout (默认值为:tickTime * 2) , maxSessionTimeout(默认值为:tickTime * 20), ticktime的默认值为2000ms。所以session范围为4s ~ 40s 。客户端: sessionTimeout,无默认值,创建实例时设置recv_timeout 值。经常会认为创建zookeeper客户端时设置了sessionTimeout为100s,而没有改变server端的配置,默认值是不会生效的。原因:客户端的zookeeper实例在创建连接时,将sessionTimeout参数发送给了服务端,服务端会根据对应的 minSession/maxSession Timeout的设置,强制修改sessionTimeout参数,也就是修改为4s~40s 返回的参数。所以服务端不一定会以客户端的sessionTImeout做为session expire管理的时间。 解决: 增加zookeeperinit recvtimeout大小的同时,需要配置tickTime的值。 tickTime设置是在 conf/zoo.cfg 文件中
The number of milliseconds of each
ticktickTime=2000 (默认) 注: tickTime 心跳基本时间单位毫秒,ZK基本上所有的时间都是这个时间的整数倍。 zookeeper连接数问题 现象: zookeeper服务器都运行正常,而客户端连接异常。 原因: 这是由于zookeeper client连接数已经超过了zookeeper server获取的配置最大连接数。所以导致zookeeper client连接失败。 解决: 修改zookeeper安装目录下 conf/zoo.cfg文件。将maxClientCnxns参数改成更大的值。 zookeeper_init函数的使用 现象: 开发人员在调用zookeeperinit函数时,若返回一个非空句柄zhandlet *zh,则认为初始化成功,这样可能会导致后续操作失败。 原因: zhandlet *zookeeperinit(const char *host, watcherfn fn, int recvtimeout,const clientidt *clientid, void *context, int flags) 函数返回一个zookeeper客户端与服务器通信的句柄,通常我们仅仅根据返回句柄情况来判断zookeeper 客户端与zookeeper服务器是否建立连接。如果句柄为空则认为是失败,非空则成功。其实不然,zookeeperinit创建与ZooKeeper服务端通信的句柄以及对应于此句柄的会话,而会话的创建是一个异步的过程,仅当会话建立成功,zookeeper_init才返回一个可用句柄。 解决: 如何正确判断zookeepr_init初始化成功,可通过以下三种方式 判断句柄的state是否为ZOOCONNECTEDSTATE状态,通过zoostate(zh)判断状态值是否为ZOOCONNECTED_STATE。
void ensureConnected()
{
pthread_mutex_lock(&lock);
while (zoo_state(zh)!=ZOO_CONNECTED_STATE)
{
pthread_cond_wait(&cond, &lock);
}
pthread_mutex_unlock(&lock);
}
在zookeeperinit中设置watcher,当zookeeper client与server会话建立后,触发watcher,当 watcher 的state = 3(ZOOCONNECTEDSTATE), type = -1(ZOOSESSION_EVENT)时,确认会话成功建立,此时zookeeper client 初始化成功,可进行后续操作。 业务上可以做保证,调用zookeeperinit返回句柄zh,通过该句柄尝试做zooexists()或zoogetdata()等操作,根据操作结果来判断是否初始化成功。 ZooKeeper服务不断重启 现象: ZooKeeper界面中ZooKeeper角色实例一直处于“未知”状态 原因: ZooKeeper所在磁盘空间不足。 ZooKeeper服务数据文件被损坏。 解决: 检查ZooKeeper磁盘空间是否足够。 删除损坏的ZooKeeper数据文件。 ZooKeeper无法对外提供服务 现象: ZooKeeper服务异常,HDFS无法启动。 原因: ZooKeeper无法选主。 ZooKeeper集群中有机器IP冲突,或主机名冲突。 解决: 检查ZooKeeper安装并运行的实例是否为奇数个,如3个、5个。 恢复故障的ZooKeeper服务。 误删ZooKeeper文件后再恢复时失败 现象: 误删了ZooKeeper文件夹,然后通过FusionInsight Manager卸载并重装ZooKeeper实例来恢复。恢复结束后,界面显示进程的健康状态为“恢复中”。 原因: 用户误删除了ZooKeeper的pid文件,例如“Hadoop-omm-quorumpeer.pid”。但是ZooKeeper的进程还在后台运行。导致恢复此实例后,该实例无法启动,状态显示为“恢复中”。 例如,删除此pid文件前,ZooKeeper实例的进程号为“6419”,删除后去恢复ZooKeeper实例,会新建一个pid文件,且起一个新的进程,进程号为“6405”。此时由于“6419”进程未清除,导致“6405”进程无法启动。 解决: 使用root用户登录ZooKeeper实例所在节点,使用kill -9old_pid命令删除进程。 old_pid表示出现错误前的进程号,您可以通过jps命令查看。 Spark 内存不足,无法退出应用程序 现象: 运行开发的应用程序时,当Driver内存不足时,Spark任务会挂起,不能退出应用程序。查看Container信息,出现以下错误:
Exception in thread "handle-read-write-executor-1" java.lang.OutOfMemoryError: Java heap space
at java.nio.HeapByteBuffer.<init>(HeapByteBuffer.java:57)
at java.nio.ByteBuffer.allocate(ByteBuffer.java:331)
at org.apache.spark.network.nio.Message$.create(Message.scala:90)
at org.apache.spark.network.nio.ReceivingConnection$Inbox.org$apache$spark$network$nio$ReceivingConnection$Inbox$$createNewMessage$1(Connection.scala:454)
at org.apache.spark.network.nio.ReceivingConnection$Inbox$$anonfun$1.apply(Connection.scala:464)
at org.apache.spark.network.nio.ReceivingConnection$Inbox$$anonfun$1.apply(Connection.scala:464)
at scala.collection.mutable.MapLike$class.getOrElseUpdate(MapLike.scala:189)
at scala.collection.mutable.AbstractMap.getOrElseUpdate(Map.scala:91)
at org.apache.spark.network.nio.ReceivingConnection$Inbox.getChunk(Connection.scala:464)
at org.apache.spark.network.nio.ReceivingConnection.read(Connection.scala:541)
at org.apache.spark.network.nio.ConnectionManager$$anon$6.run(ConnectionManager.scala:198)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
原因:
因为提供给应用程序的Driver内存不足,导致内存空间出现full gc(全量垃圾回收)。但Garbage Collectors未能及时清理内存空间,使得full gc状态一直存在,导致了应用程序不能退出。
解决:
执行命令强制将任务退出,然后通过修改内存参数的方式解决内存不足的问题,使任务执行成功。
针对此类数据量大的任务,希望任务不再挂起,遇到内存不足时,直接提示任务运行失败。
org.apache.spark.shuffle.FetchFailedException
现象:
这种问题一般发生在有大量shuffle操作的时候,task不断的failed,然后又重执行,一直循环下去,非常的耗时。
missing output location org.apache.spark.shuffle.MetadataFetchFailedException: Missing an output location for shuffle 0
shuffle fetch faild
org.apache.spark.shuffle.FetchFailedException: Failed to connect to spark047215/192.168.47.215:50268
当前的配置为每个executor使用1cpu,5GRAM,启动了20个executor
解决:
一般遇到这种问题提高executor内存即可,同时增加每个executor的cpu,这样不会减少task并行度。
spark.executor.memory 15G
spark.executor.cores 3
spark.cores.max 21
启动的execuote数量为:7个
execuoteNum = spark.cores.max/spark.executor.cores
每个executor的配置:
3core,15G RAM
消耗的内存资源为:105G RAM
15G*7=105G
可以发现使用的资源并没有提升,但是同样的任务原来的配置跑几个小时还在卡着,改了配置后几分钟就结束了。
spark.executor.memoryOverhead
现象:
堆外内存(默认是executor内存的10%),当数据量比较大的时候,如果按默认的就会有下面的异常,导致程序崩溃
Container killed by YARN for exceeding memory limits. 1.8 GB of 1.8 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead.
解决:
具体值根据实际情况配置
新版:
--conf spark.executor.memoryOverhead=2048
旧版:
--conf spark.yarn.executor.memoryOverhead=2048
新版如果用旧版,会:
WARN SparkConf: The configuration key 'spark.yarn.executor.memoryOverhead' has been deprecated as of Spark 2.3 and may be removed in the future. Please use the new key 'spark.executor.memoryOverhead' instead.
No more replicas available for rdd
现象:
 解决:
增大executor的内存
--executor-memory 4G
Executor&Task Lost
现象:
因为网络或者gc的原因,worker或executor没有接收到executor或task的心跳反馈
executor lost
WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local): ExecutorLostFailure (executor lost)
task lost
WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217): java.io.IOException: Connection from /192.168.47.217:55483 closed
各种timeout
java.util.concurrent.TimeoutException: Futures timed out after [120 second
ERROR TransportChannelHandler: Connection to /192.168.47.212:35409 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong
解决:
提高 spark.network.timeout 的值,根据情况改成300(5min)或更高。
默认为 120(120s),配置所有网络传输的延时,如果没有主动设置以下参数,默认覆盖其属性
spark.core.connection.ack.wait.timeout
spark.akka.timeout
spark.storage.blockManagerSlaveTimeoutMs
spark.shuffle.io.connectionTimeout
spark.rpc.askTimeout or spark.rpc.lookupTimeout
倾斜
现象:
大多数任务都完成了,还有那么一两个任务怎么都跑不完或者跑的很慢。
分为数据倾斜和task倾斜两种。
解决:
数据倾斜
数据倾斜大多数情况是由于大量null值或者""引起,在计算前过滤掉这些数据既可。
sqlContext.sql("...where col is not null and col != ''")
任务倾斜
task倾斜原因比较多,网络io,cpu,mem都有可能造成这个节点上的任务执行缓慢,可以去看该节点的性能监控来分析原因。以前遇到过同事在spark的一台worker上跑R的任务导致该节点spark task运行缓慢。
或者可以开启spark的推测机制,开启推测机制后如果某一台机器的几个task特别慢,推测机制会将任务分配到其他机器执行,***Spark会选取最快的作为最终结果。
spark.speculation true
spark.speculation.interval 100 - 检测周期,单位毫秒;
spark.speculation.quantile 0.75 - 完成task的百分比时启动推测
spark.speculation.multiplier 1.5 - 比其他的慢多少倍时启动推测。
大数据计算时出现“Channel空闲超时”
在10节点集群,30T数据量下,执行tpcds测试时,出现如下错误。
Connection to 10.10.10.1 has been quiet for 123450 ms while there are still 5 outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong.
原因:
当Map Server繁忙时,Reduce Client发出请求,得不到响应。当等待时间超过一个阈值时,出现错误。默认的时间为120秒。
解决:
上述问题是在request个数很大时发生的,属于正常现象。解决措施有两种:
将spark.shuffle.io.connectionTimeout参数调大。10节点、30T数据的TPCDS测试中设置为2000s,运行正常。此参数与spark.network.timeout配合使用,优先使用spark.shuffle.io.connectionTimeout参数设置的值。如果spark.shuffle.io.connectionTimeout未设置,则使用spark.network.timeout的参数值。
调大spark.shuffle.io.serverThreads来解决,将此参数的值设置为core个数的两倍。
Spark任务运行失败,ApplicationMaster出现物理内存溢出异常
现象:
在YARN上运行Spark任务失败,ApplicationMaster出现物理内存溢出异常。报错内容如下:
原因:
日志中显示“Killing container”,直接原因是物理内存使用超过了限定值,YARN的NodeManager监控到内存使用超过阈值,强制终止该container进程。
解决:
在Spark客户端“spark-defaults.conf”配置文件中增加如下参数,或者在提交命令时添加--conf指定如下参数,来增大memoryOverhead。
spark.yarn.driver.memoryOverhead:设置堆外内存大小(cluster模式使用)。
spark.yarn.am.memoryOverhead:设置堆外内存大小(client模式使用)。
执行Spark SQL语句时,出现joinedRow.isNullAt的空指针异常
现象:
在执行Spark SQL语句时,出现“joinedRow.isNullAt”的空指针异常,异常信息如下所示。
解决:
增大executor的内存
--executor-memory 4G
Executor&Task Lost
现象:
因为网络或者gc的原因,worker或executor没有接收到executor或task的心跳反馈
executor lost
WARN TaskSetManager: Lost task 1.0 in stage 0.0 (TID 1, aa.local): ExecutorLostFailure (executor lost)
task lost
WARN TaskSetManager: Lost task 69.2 in stage 7.0 (TID 1145, 192.168.47.217): java.io.IOException: Connection from /192.168.47.217:55483 closed
各种timeout
java.util.concurrent.TimeoutException: Futures timed out after [120 second
ERROR TransportChannelHandler: Connection to /192.168.47.212:35409 has been quiet for 120000 ms while there are outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong
解决:
提高 spark.network.timeout 的值,根据情况改成300(5min)或更高。
默认为 120(120s),配置所有网络传输的延时,如果没有主动设置以下参数,默认覆盖其属性
spark.core.connection.ack.wait.timeout
spark.akka.timeout
spark.storage.blockManagerSlaveTimeoutMs
spark.shuffle.io.connectionTimeout
spark.rpc.askTimeout or spark.rpc.lookupTimeout
倾斜
现象:
大多数任务都完成了,还有那么一两个任务怎么都跑不完或者跑的很慢。
分为数据倾斜和task倾斜两种。
解决:
数据倾斜
数据倾斜大多数情况是由于大量null值或者""引起,在计算前过滤掉这些数据既可。
sqlContext.sql("...where col is not null and col != ''")
任务倾斜
task倾斜原因比较多,网络io,cpu,mem都有可能造成这个节点上的任务执行缓慢,可以去看该节点的性能监控来分析原因。以前遇到过同事在spark的一台worker上跑R的任务导致该节点spark task运行缓慢。
或者可以开启spark的推测机制,开启推测机制后如果某一台机器的几个task特别慢,推测机制会将任务分配到其他机器执行,***Spark会选取最快的作为最终结果。
spark.speculation true
spark.speculation.interval 100 - 检测周期,单位毫秒;
spark.speculation.quantile 0.75 - 完成task的百分比时启动推测
spark.speculation.multiplier 1.5 - 比其他的慢多少倍时启动推测。
大数据计算时出现“Channel空闲超时”
在10节点集群,30T数据量下,执行tpcds测试时,出现如下错误。
Connection to 10.10.10.1 has been quiet for 123450 ms while there are still 5 outstanding requests. Assuming connection is dead; please adjust spark.network.timeout if this is wrong.
原因:
当Map Server繁忙时,Reduce Client发出请求,得不到响应。当等待时间超过一个阈值时,出现错误。默认的时间为120秒。
解决:
上述问题是在request个数很大时发生的,属于正常现象。解决措施有两种:
将spark.shuffle.io.connectionTimeout参数调大。10节点、30T数据的TPCDS测试中设置为2000s,运行正常。此参数与spark.network.timeout配合使用,优先使用spark.shuffle.io.connectionTimeout参数设置的值。如果spark.shuffle.io.connectionTimeout未设置,则使用spark.network.timeout的参数值。
调大spark.shuffle.io.serverThreads来解决,将此参数的值设置为core个数的两倍。
Spark任务运行失败,ApplicationMaster出现物理内存溢出异常
现象:
在YARN上运行Spark任务失败,ApplicationMaster出现物理内存溢出异常。报错内容如下:
原因:
日志中显示“Killing container”,直接原因是物理内存使用超过了限定值,YARN的NodeManager监控到内存使用超过阈值,强制终止该container进程。
解决:
在Spark客户端“spark-defaults.conf”配置文件中增加如下参数,或者在提交命令时添加--conf指定如下参数,来增大memoryOverhead。
spark.yarn.driver.memoryOverhead:设置堆外内存大小(cluster模式使用)。
spark.yarn.am.memoryOverhead:设置堆外内存大小(client模式使用)。
执行Spark SQL语句时,出现joinedRow.isNullAt的空指针异常
现象:
在执行Spark SQL语句时,出现“joinedRow.isNullAt”的空指针异常,异常信息如下所示。
6/09/08 11:04:11 WARN TaskSetManager: Lost task 1.0 in stage 7.0 (TID 10, vm1, 1): java.lang.NullPointerException
at org.apache.spark.sql.catalyst.expressions.JoinedRow.isNullAt(JoinedRow.scala:70)
at org.apache.spark.sql.catalyst.expressions.GeneratedClass$SpecificMutableProjection.apply(Unknown Source)
at org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator$$anonfun$generateProcessRow$1.apply(TungstenAggregationIterator.scala:194)
at org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator$$anonfun$generateProcessRow$1.apply(TungstenAggregationIterator.scala:192)
at org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator.processInputs(TungstenAggregationIterator.scala:372)
at org.apache.spark.sql.execution.aggregate.TungstenAggregationIterator.start(TungstenAggregationIterator.scala:626)
at org.apache.spark.sql.execution.aggregate.TungstenAggregate$$anonfun$doExecute$1.org$apache$spark$sql$execution$aggregate$TungstenAggregate$$anonfun$$executePartition$1(TungstenAggregate.scala:135)
at org.apache.spark.sql.execution.aggregate.TungstenAggregate$$anonfun$doExecute$1$$anonfun$3.apply(TungstenAggregate.scala:144)
at org.apache.spark.sql.execution.aggregate.TungstenAggregate$$anonfun$doExecute$1$$anonfun$3.apply(TungstenAggregate.scala:144)
at org.apache.spark.rdd.MapPartitionsWithPreparationRDD.compute(MapPartitionsWithPreparationRDD.scala:64)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:334)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:267)
at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:334)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:267)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:75)
at org.apache.spark.scheduler.ShuffleMapTask.runTask(ShuffleMapTask.scala:42)
at org.apache.spark.scheduler.Task.run(Task.scala:90)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:253)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
原因: 由如下日志信息可知,该错误是由于内存不足,导致buffer在申请内存时申请失败返回为null,对null进行操作就返回了空指针异常。 当集群中内存相关的关键配置项的值设置的比较小时,例如设置为如下所示的值:
spark.executor.cores = 8
spark.executor.memory = 512M
spark.buffer.pageSize = 16M
此时,执行任务会出现内存申请失败返回null的异常,关键日志如下:
6/09/08 11:04:11 WARN TaskSetManager: Lost task 1.0 in stage 7.0 (TID 10, vm1, 1): java.lang.NullPointerException
at org.apache.spark.sql.catalyst.expressions.JoinedRow.isNullAt(JoinedRow.scala:70)
解决: 根据executor日志提示信息,您可以通过调整如下两个参数解决此问题。在客户端的“spark-defaults.conf”配置文件中调整如下参数。 spark.executor.memory:增加executor的内存,即根据实际业务量,适当增大“spark.executor.memory”的参数值。需满足公式:spark.executor.memory > spark.buffer.pageSize * (num * spark.executor.cores) / spark.shuffle.memoryFraction / spark.shuffle.safetyFraction spark.executor.cores:减小executor的核数,即减小executor-cores的参数值。需满足公式:spark.executor.cores < spark.executor.memory / spark.buffer.pageSize / num * spark.shuffle.memoryFraction * spark.shuffle.memoryFraction。 在调整这两个参数时,需满足spark.executor.memory * spark.shuffle.memoryFraction *spark.shuffle.safetyFraction / (num * spark.executor.cores) > spark.buffer.pageSize公式,在内存充足的情况下,建议直接将常数num设置为16,可解决所有场景遇到的内存问题。 出现java.io.FileNotFoundException异常 现象: 任务开始执行时,Driver端出现以下错误。
java.io.FileNotFoundException: /opt/huawei/Bigdata/FusionInsight/FusionInsight-Spark-1.5.0/spark/conf/log4j.properties (No such file or directory)
at java.io.FileInputStream.open(Native Method)
at java.io.FileInputStream.<init>(FileInputStream.java:146)
at java.io.FileInputStream.<init>(FileInputStream.java:101)
at sun.net.www.protocol.file.FileURLConnection.connect(FileURLConnection.java:90)
原因:
“spark.driver.extraJavaOption”配置值仅适用于Driver端的JVM参数配置。在使用yarn_client的模式时,需要将此配置值替换为客户端的实际路径。
当出现此错误时,不影响任务的执行。
解决:
在客户端的安装目录下,修改“spark-defaults.conf”文件,将“spark.driver.extraJavaOption”客户端机器的log4j的配置文件路径和名称。
cd $/Spark/spark/conf
vi spark-defaults.conf
修改配置参数(如果该参数的值为空,执行命令时,会使用本地默认的log4j的配置路径):
spark.driver.extraJavaOptions = -Dlog4j.configuration=file:/home/client/Spark/spark/conf/log4j.properties -Dlog4j.configuration.watch=false
ElasticSearch
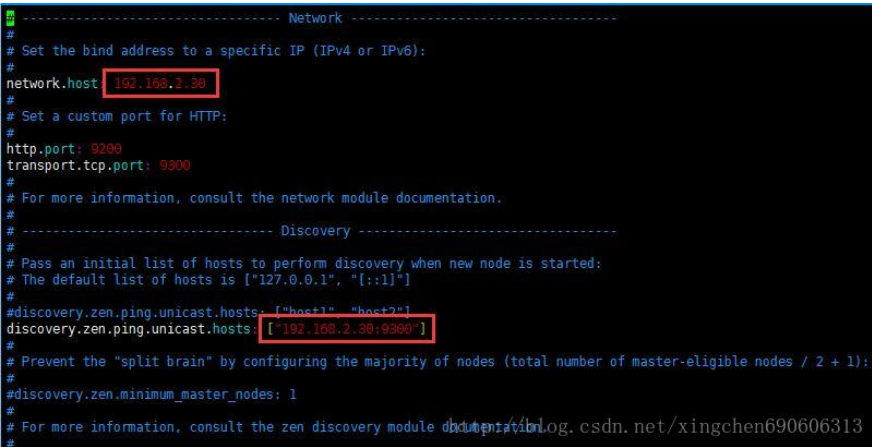
无法指定被请求的地址
现象:
 原因:
elasticsearch.yml文件的参数配置不正确
解决:
编辑node节点对应的配置文件,例如:
(1)在命令行输入:vim /usr/elk/elasticsearch/elasticsearch-master/config/elasticsearch.yml
(2)打开文件后,把文件中的这两个地方的IP地址改成ES所在服务器的IP地址即可。
原因:
elasticsearch.yml文件的参数配置不正确
解决:
编辑node节点对应的配置文件,例如:
(1)在命令行输入:vim /usr/elk/elasticsearch/elasticsearch-master/config/elasticsearch.yml
(2)打开文件后,把文件中的这两个地方的IP地址改成ES所在服务器的IP地址即可。
org.elasticsearch.bootstrap.StartupException: java.lang.RuntimeException: can not run elasticsearch as root
原因:
因为安全问题elasticsearch不让用root用户直接运行,所以要创建新用户
解决:
创建一个单独的用户用来运行ElasticSearch
max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
原因:
普通用户执行问题
解决:
切换到root用户,编辑/etc/security/limits.conf 添加 elk hard nofile 65536
elk soft nofile 65536 (elk是用户名)
org.elasticsearch.transport.RemoteTransportException: Failed to deserialize exception response from stream
原因:
es节点之间的JDK版本不一样
解决:
统一JDK版本和环境
由gc引起节点脱离集群
原因:
因为gc时会使jvm停止工作,如果某个节点gc时间过长,master ping3次(zen discovery默认ping失败重试3次)不通后就会把该节点剔除出集群,从而导致索引进行重新分配。
解决:
优化gc,减少gc时间。
调大zen discovery的重试次数(es参数:pingretries)和超时时间(es参数:pingtimeout)。后来发现根本原因是有个节点的系统所在硬盘满了。导致系统性能下降。
ES索引设置不当
集群名称配置
ES启动的默认群集名称称为elasticsearch。如果群集中有许多节点,最好保持命名标志尽可能一致,例如:
cluster.name:app_es_production
node.name:app_es_node_001
集群恢复设置
节点的恢复设置也很重要。假设群集中的某些节点由于故障而重新启动,并且某些节点在其他节点之后重启。为了使所有这些节点之间的数据保持一致,我们必须运行一致性程序,以使所有集群保持一致状态。
举例1:只要10个数据或主节点已加入群集,即可恢复。
gateway.recover_after_nodes:10
举例2:集群中期待启动节点达到20个以及时间超过7分钟后,集群重启或恢复。
gateway.expected_nodes:20
gateway.recover_after_time:7m
使用正确的配置,可能需要数小时的恢复缩减到只需要分钟级,极大提高工作效率。
防脑裂配置
minimum_master_nodes对于群集稳定性非常重要。它们有助于防止脑裂。此设置的建议值为(N / 2)+ 1 ,其中N是候选主节点的节点数。有了这个,如果你有10个可以保存数据并成为主数据的候选主节点,那么该值将是6。如果您有三个专用主节点和1,000个数据节点,则该值为两个(仅计算候选主节点): discovery.zen.minimummasternodes:2
Solr
Solr客户端无法实时索引
原因:
Solr客户端写索引失败,异常信息如下:
Error from server at https://192.168.152.14:21104/solr/col_test_shard1_replica2: Exception writing document id 6907a8e1154a4bdb9a4238cd7bb874c4 to the index; possible analysis error., retry? 0
原因:
索引文件损坏。
索引文件所在磁盘或文件系统故障。
解决:
查看“/var/log/Bigdata/solr”下SolrServer1的日志“solr-主机名.log”。在日志中搜索关键词“IndexWriter AlreadyCloseException”。
Hue
Hue的页面打不开
现象:
Hue服务组件的Hue WebUI页面打不开。
原因:
端口未对外开放。
浮动IP配置错误。
解决:
在浏览器所在的本地机器,通过命令行执行telnet指令,查看端口是否开放。
在Hue所在节点执行ifconfig,查看配置的浮动IP是否生效。
恢复该故障大概需要10分钟。
HUE中Hive 查询有问题
现象:
Could not connect to localhost:10000 或者 Could not connect to bigdatamaster:10000
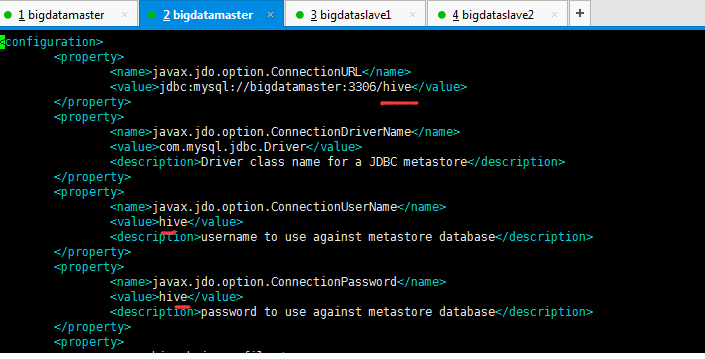
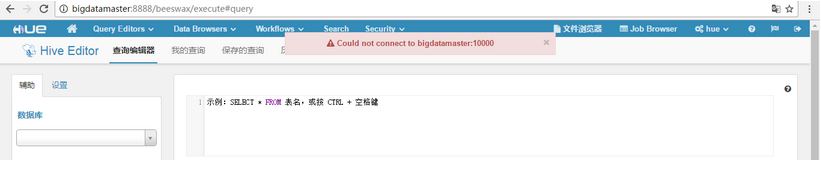 解决:
hive-site.xml里的配置信息
解决:
hive-site.xml里的配置信息
 在hue里面查看HDFS文件浏览器报错
现象:
当前用户没有权限查看,
cause:org.apache.Hadoop.ipc.StandbyException: Operation category READ is not supported in state standby
解决:
Web页面查看两个NameNode状态,是不是之前的namenode是standby状态了. 我现有的集群就是这种情况, 由于之前的服务是master1起的, 挂了之后自动切换到master2, 但是hue中webhdfs还是配置的master1,导致在hue中没有访问权限.
hue使用mysql作为元数据库
现象:
hue默认使用sqlite作为元数据库,不推荐在生产环境中使用。会经常出现database is lock的问题。
解决:
先在mysql里面创建数据库hue,然后修改hue.ini
在hue里面查看HDFS文件浏览器报错
现象:
当前用户没有权限查看,
cause:org.apache.Hadoop.ipc.StandbyException: Operation category READ is not supported in state standby
解决:
Web页面查看两个NameNode状态,是不是之前的namenode是standby状态了. 我现有的集群就是这种情况, 由于之前的服务是master1起的, 挂了之后自动切换到master2, 但是hue中webhdfs还是配置的master1,导致在hue中没有访问权限.
hue使用mysql作为元数据库
现象:
hue默认使用sqlite作为元数据库,不推荐在生产环境中使用。会经常出现database is lock的问题。
解决:
先在mysql里面创建数据库hue,然后修改hue.ini
[[database]]
engine=mysql
host=slave1
port=3306
user=Hadoop
password=Hadoop
name=hue
完成以上的这个配置,启动Hue,通过浏览器访问,会发生错误,原因是mysql数据库没有被初始化
DatabaseError: (1146, "Table 'hue.desktop_settings' doesn't exist")
初始化数据库
cd hue-release-3.11.0/build/env/
bin/hue syncdb
bin/hue migrate
执行完以后,可以在mysql中看到,hue相应的表已经生成。
启动hue, 能够正常访问了
开启hbase查询模块
解决:
需要在hbase集群已经启动的基础上,再启动thrift,默认端口为9090
hbase-daemon.sh start thrift
修改配置hue.ini的配置文件
[hbase]
hbase_clusters=(Cluster|master1:9090)
hbase_conf_dir=/usr/hbase-1.1.6/conf
Cluster 为在Hue展现中的名字,可配置多个hbase集群
master1:9090 hbase启动的thrift主机及端口
hive查询报错TTransportException
现象:
在hue里面查询hive数据,之前一直使用正常,突然就查询不了,一直转不出结果最后页面可能还会报504 Gateway Time-out。查看日志定位error:
Could not connect to localhost:9090 (code THRIFTTRANSPORT): TTransportException('Could not connect to localhost:9090',)
解决:
看来可能是thrift服务器通信的原因,重启了hive的hiveserver2进程,问题解决。
nohup bin/hiveserver2 &
Filesystem root ‘/’ should be owned by ‘hdfs’
原因:
hue 文件系统根目录“/”应归属于“hdfs”
解决:
修改文件desktop/libs/Hadoop/src/Hadoop/fs/webhdfs.py 中的 DEFAULTHDFSSUPERUSER = ‘hdfs’ 更改为你的Hadoop用户
安装启动异常
scp传秘钥的时候报错Permission denied (publickey).
 解决:将秘钥先复制到跳板机上,然后再从跳板机复制到你所要到的目的机
[root@vm172-31-100-17 .ssh]# scp -p ./id_rsa.pub root@10.69.64.93:/root/
解决:将秘钥先复制到跳板机上,然后再从跳板机复制到你所要到的目的机
[root@vm172-31-100-17 .ssh]# scp -p ./id_rsa.pub root@10.69.64.93:/root/
 [root@jumpserver ~]# scp -i /root/.ssh/id_rsa_ccb /root/id_rsa.pub root@172.31.100.6:/root/.ssh/
[root@jumpserver ~]# scp -i /root/.ssh/id_rsa_ccb /root/id_rsa.pub root@172.31.100.6:/root/.ssh/
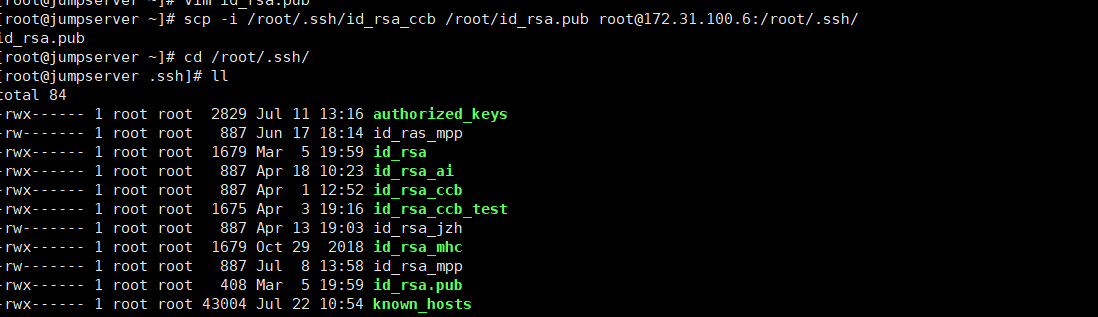
[root@vm172-31-100-6 .ssh]# cat ./id_rsa.pub >> authorized_keys

 ambari启动:ERROR: Exiting with exit code -1.
ambari启动:ERROR: Exiting with exit code -1.
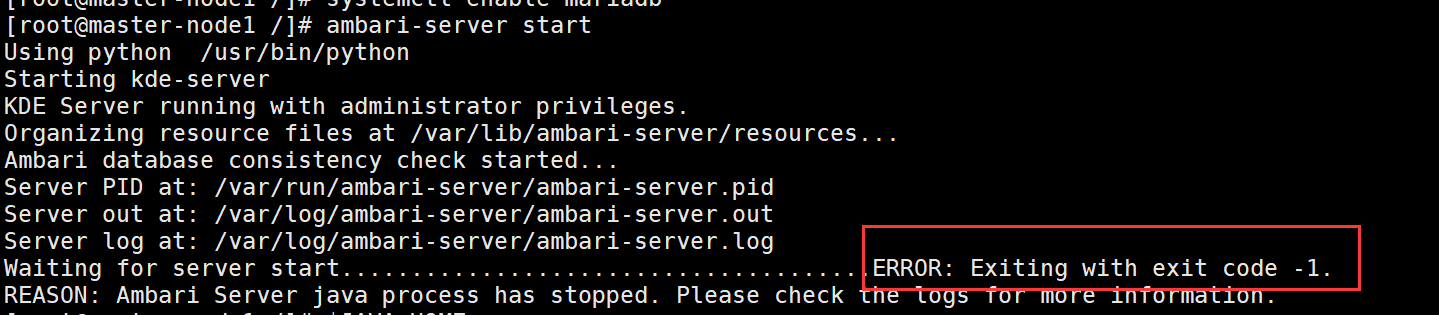 原因:mariadb数据库没有设置开机自启动
解决:
[root@master-node1 /]# systemctl start mariadb
[root@master-node1 /]# systemctl enable mariadb
原因:mariadb数据库没有设置开机自启动
解决:
[root@master-node1 /]# systemctl start mariadb
[root@master-node1 /]# systemctl enable mariadb