程序准备 任务源码,点击这里下载 准备输入文件 格式要求 任意字符串,彼此用空格作为分隔符 若干行,也可以直接用 spark 包下面的README.md文件 上传所需 jar 包以及要处理的输入文件 将生成的 jar 包和待处理的文件 in.file ,通过xftp上传至 MASTER 主机,假设目录为/home/spark 将 in.file 文件上传至 HDFS ,命令如下:
# sudo -u hdfs hdfs dfs -mkdir -p /user/YOURNAME/testdata/input
# sudo -u hdfs hdfs dfs -put /home/spark/in.file /user/YOURNAME/testdata/input
注意:第一条命令为创建文件输入目录,请勿自行创建文件输出目录;另外,在执行第二条命令前请检查当前所在目录
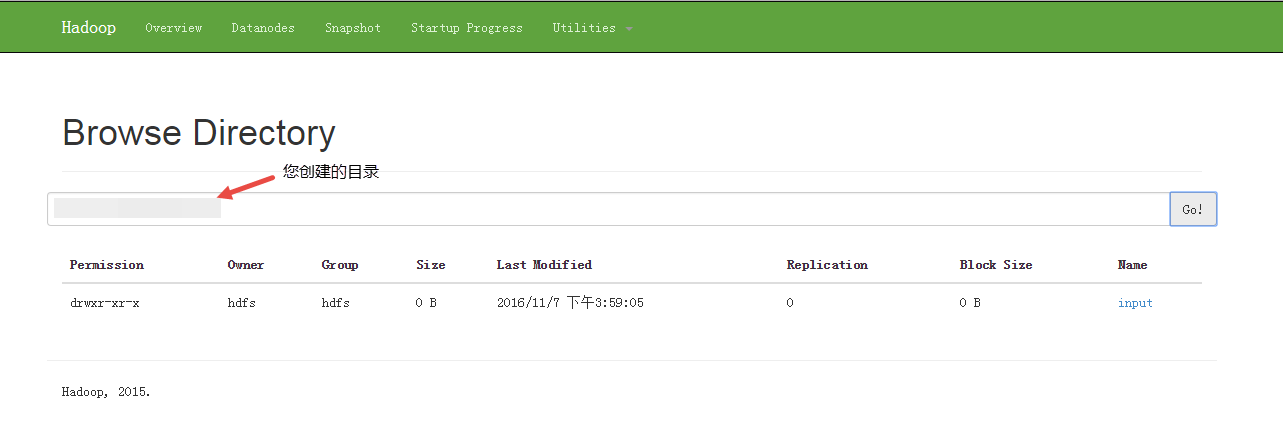
通过 Ambari > HDFS > Quick Links >任意一activity集群> NameNode UI > Utilities > Browse the file system 可以访问 HDFS 的 WEB 界面查看文件是否上传成功以及输出的文件,如下图所示
 也可通过以下命令查看
也可通过以下命令查看
# sudo -u hdfs dfs -ls /user/YOURNAME/testdata/input
任务提交 执行下方指令即可
local(file on hdfs)
# sudo -u spark spark-submit --class com.托管Hadoop.demo.WordCount --master local[2] wordcount-1.0-SNAPSHOT.jar "/user/YOURNAME/testdata/input" "/user/YOURNAME/testdata/output"
yarn-client(inputfile on local,outputfile on hdfs)
#sudo -u spark spark-submit --class com.托管Hadoop.demo.WordCount --master yarn-client /home/spark/wordcount-1.0-SNAPSHOT.jar file:///usr/hdp/2.4.0.0-169/spark/README.md hdfs:///user/YOURNAME/output
yarn-cluster(file on hdfs)
# sudo -u spark spark-submit --class com.托管Hadoop.demo.WordCount --master yarn --deploy-mode cluster /home/spark/wordcount-1.0-SNAPSHOT.jar "/user/YOURNAME/testdata/input" "/user/YOURNAME/testdata/output"
查询结果
在命令行中查询
在执行完命令后,在屏幕的打印信息中可以找到相应内容,如下图所示
 在Ambari控制台查询
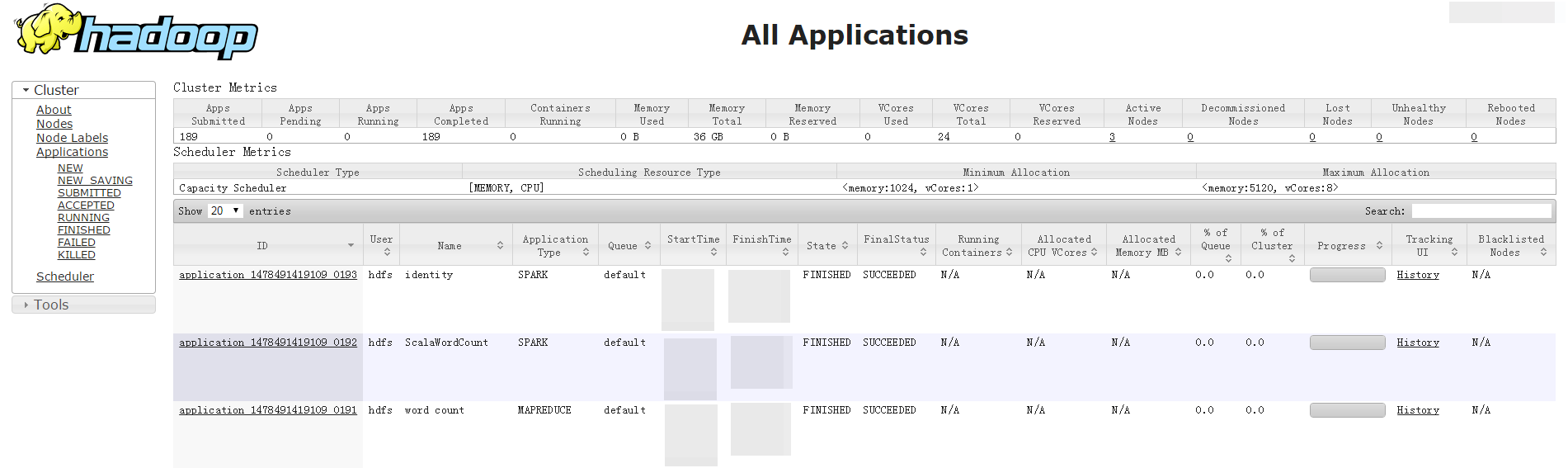
任务完成后以在集群详情页 -> Ambari控制台 -> YARN -> Quicklinks ->集群ID -> ResourceManager 查询,结果如下图所示
在Ambari控制台查询
任务完成后以在集群详情页 -> Ambari控制台 -> YARN -> Quicklinks ->集群ID -> ResourceManager 查询,结果如下图所示