
 工作流是数据挖掘组件提供的可视化模型开发方式,用户可以通过拖拽算子的方式来构建模型训练过程。工作流列表页面显示现有的工作流的信息。
新建工作流
工作流是数据挖掘组件提供的可视化模型开发方式,用户可以通过拖拽算子的方式来构建模型训练过程。工作流列表页面显示现有的工作流的信息。
新建工作流
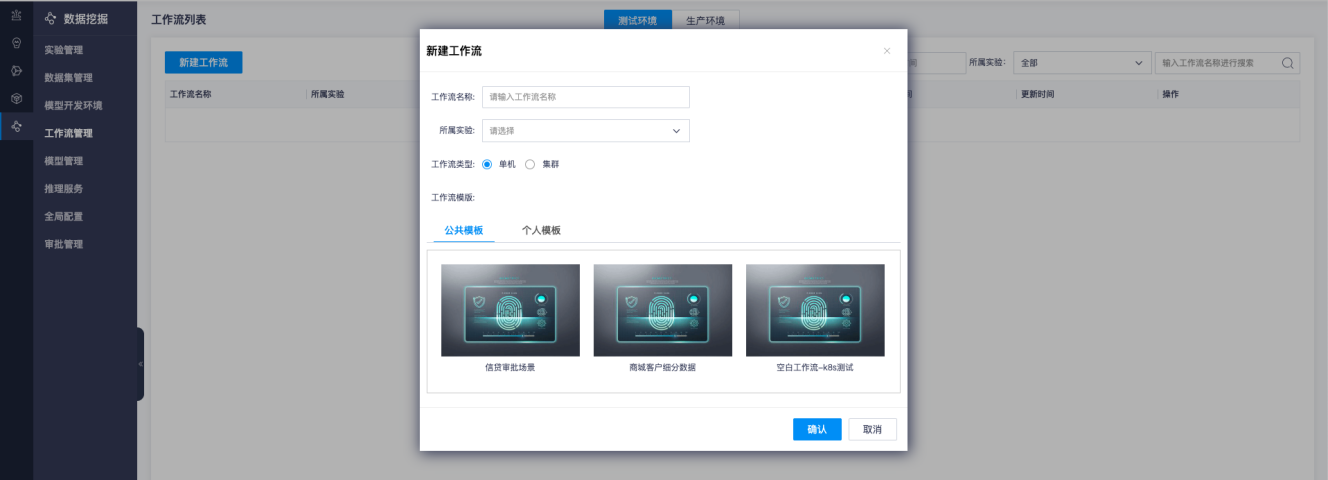 点击【新建工作流】按钮进入工作流创建页面,新建工作流需要指定工作流名称,所属实验,工作流类型以及所用的模板。
工作流根据底层资源的不同分为单机和集群版本。单机版提供sklearn、lightGBM、XGBoost等算法框架封装的算子,集群版提供SparkMLlib封装的算子。
工作流模板支持平台提供的公共模板与个人保存的个人模板。
点击【新建工作流】按钮进入工作流创建页面,新建工作流需要指定工作流名称,所属实验,工作流类型以及所用的模板。
工作流根据底层资源的不同分为单机和集群版本。单机版提供sklearn、lightGBM、XGBoost等算法框架封装的算子,集群版提供SparkMLlib封装的算子。
工作流模板支持平台提供的公共模板与个人保存的个人模板。
 新建完成的工作流会出现的工作流列表中,工作流列表支持的操作包括:
删除:删除对应工作流
发布到生产(仅测试环境有效):将工作流从测试环境发布到生产环境。
新建完成的工作流会出现的工作流列表中,工作流列表支持的操作包括:
删除:删除对应工作流
发布到生产(仅测试环境有效):将工作流从测试环境发布到生产环境。
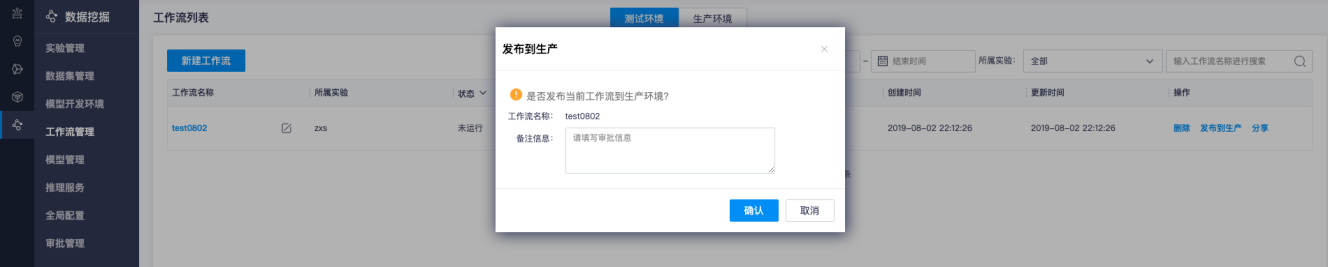 点击发布到生产,需要填写备注信息,需要由项目管理员审批,相关审批请求需要进入审批管理界面查看。
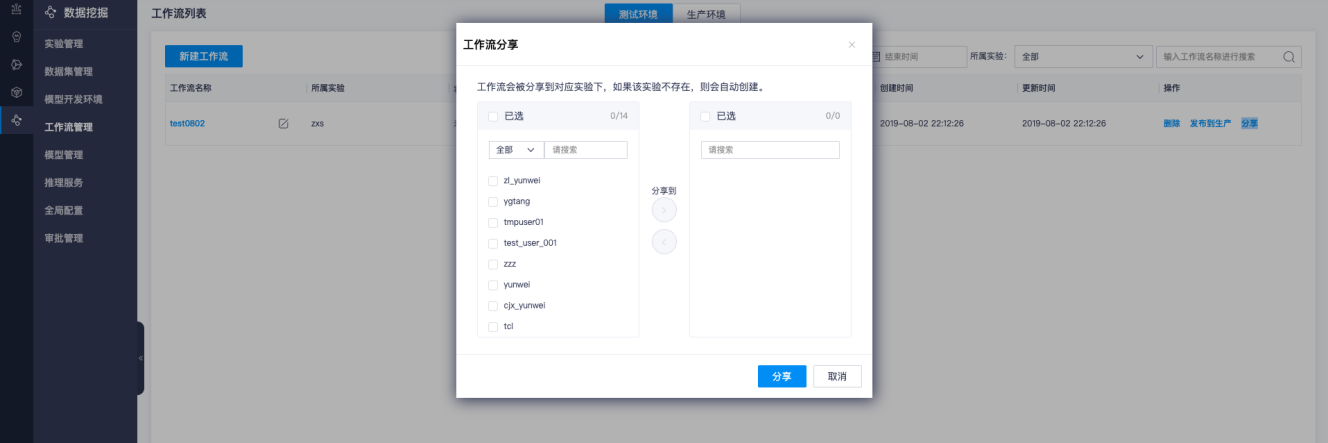
分享:将指定工作流分享给指定用户
点击发布到生产,需要填写备注信息,需要由项目管理员审批,相关审批请求需要进入审批管理界面查看。
分享:将指定工作流分享给指定用户
 编辑工作流
编辑工作流
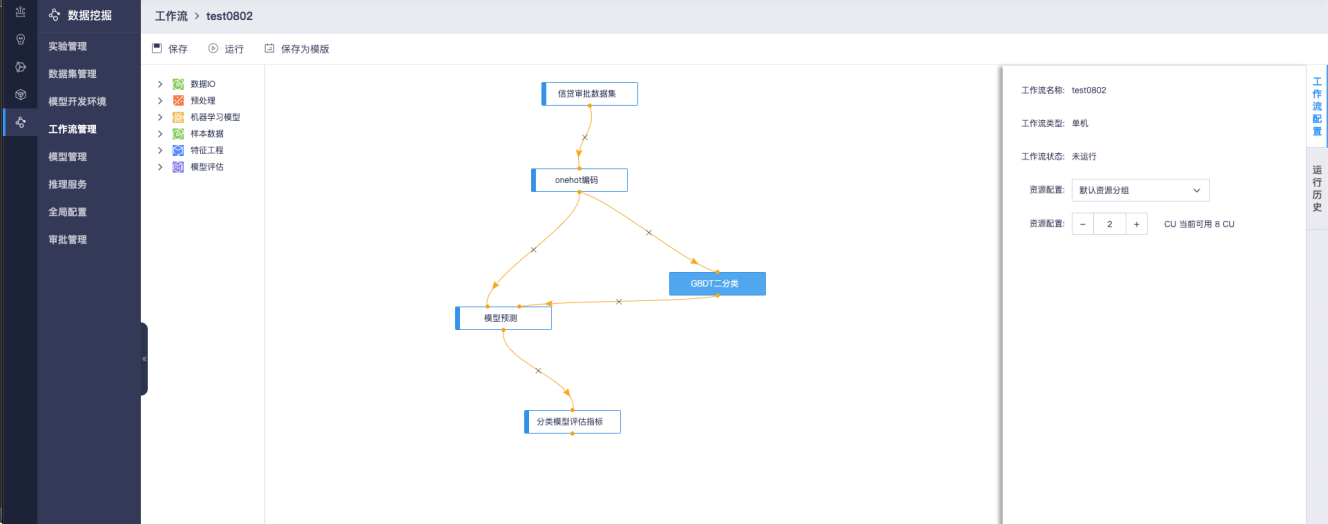
 在工作流列表页面点击工作流名称可以进入工作流编辑页面。
工作流编辑页面分为左中右三个区域。
左侧为算子区,显示当前工作流支持的所有算子。
中间为画布区,用于构建数据挖掘工作流。
右侧为属性区,用于显示算子或工作流的属性。
点击右侧的工作流配置,可以设置工作流的属性,例如工作流使用的资源等。
在工作流列表页面点击工作流名称可以进入工作流编辑页面。
工作流编辑页面分为左中右三个区域。
左侧为算子区,显示当前工作流支持的所有算子。
中间为画布区,用于构建数据挖掘工作流。
右侧为属性区,用于显示算子或工作流的属性。
点击右侧的工作流配置,可以设置工作流的属性,例如工作流使用的资源等。
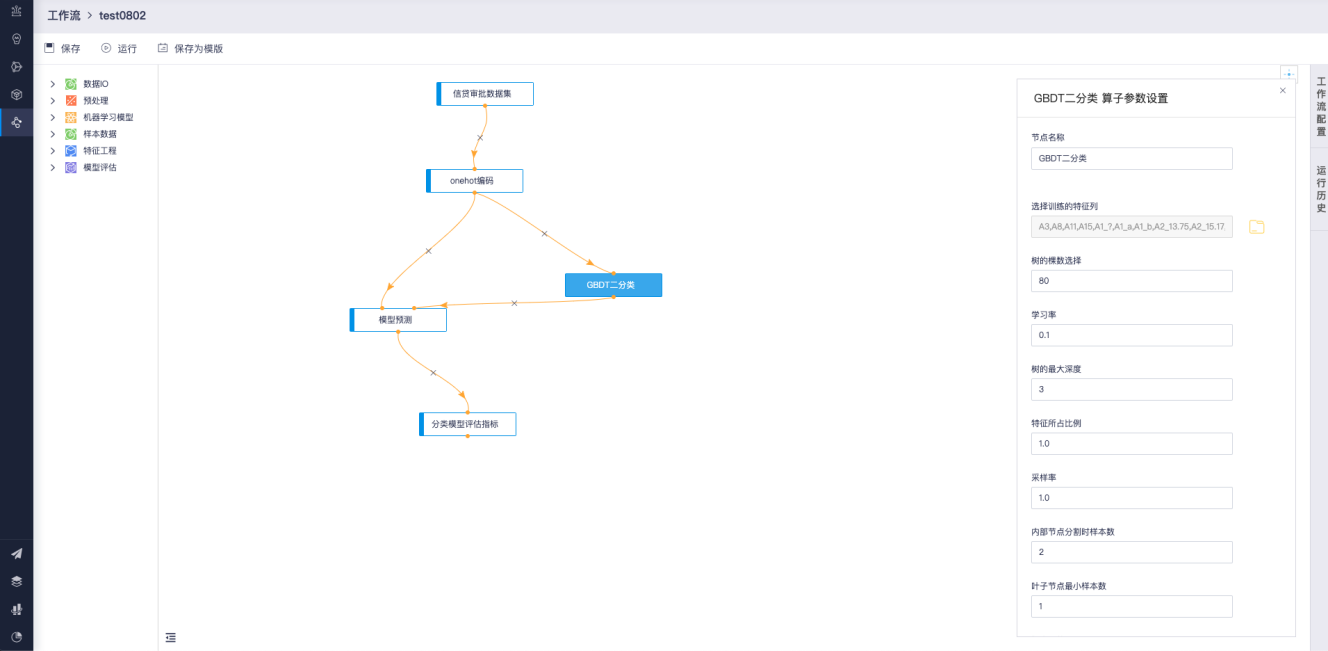
 双击算子,右侧会显示算子的属性。根据算子的不同,算子可以配置的属性也不同,例如对于模型类算子GBDT二分类的算子主要是算法的超参数设置。
双击算子,右侧会显示算子的属性。根据算子的不同,算子可以配置的属性也不同,例如对于模型类算子GBDT二分类的算子主要是算法的超参数设置。
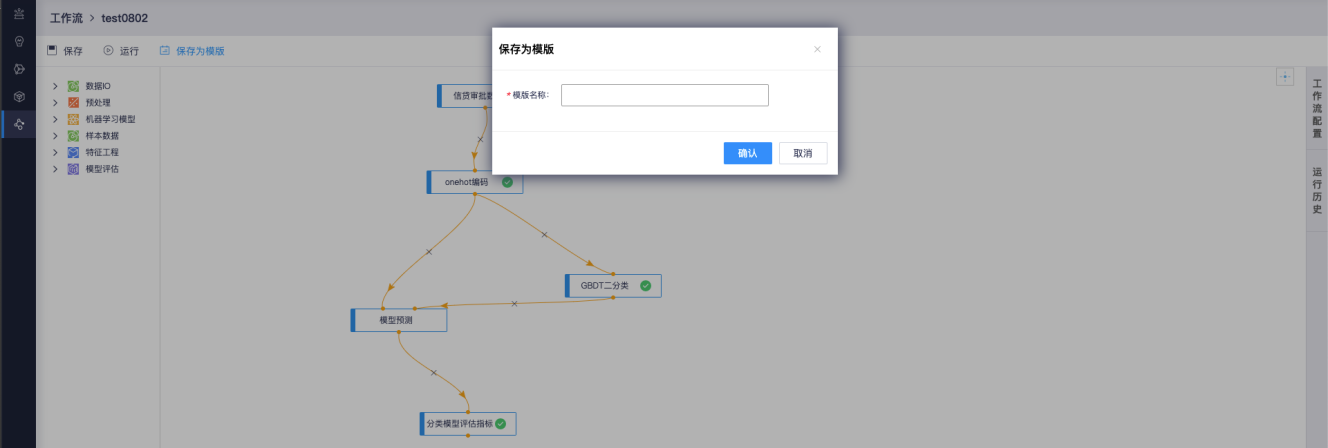
 工作流顶部是工作流的操作区域,可以对工作流进行保存、运行以及将工作流保存为个人模板。
工作流顶部是工作流的操作区域,可以对工作流进行保存、运行以及将工作流保存为个人模板。
 算子上点击右键,可以对算子进行更多的操作,不同的算子支持的右键操作略有差别。
算子上点击右键,可以对算子进行更多的操作,不同的算子支持的右键操作略有差别。
 编辑:编辑算子参数;
删除:删除当前算子;
运行:可以指定运行完整工作流、运行到此处或者运行此算子。
算子和算子之间可以通过连线进行连接,通过点x符号可以删除算子之间的连线。
编辑:编辑算子参数;
删除:删除当前算子;
运行:可以指定运行完整工作流、运行到此处或者运行此算子。
算子和算子之间可以通过连线进行连接,通过点x符号可以删除算子之间的连线。
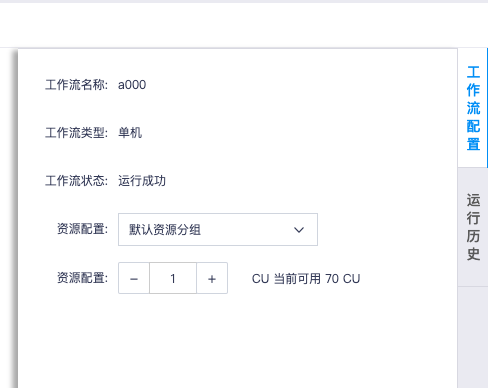
 运行工作流
工作流运行需要指定运行工作流所需的资源CU/DCU,才能进行运行。工作流的资源配置在右侧的工作流配置中指定。
运行工作流
工作流运行需要指定运行工作流所需的资源CU/DCU,才能进行运行。工作流的资源配置在右侧的工作流配置中指定。
 工作流的运行有两种方式,一种是通过右上的全部运行。另一种是通过算子上右键来进行运行。
工作流的运行有两种方式,一种是通过右上的全部运行。另一种是通过算子上右键来进行运行。
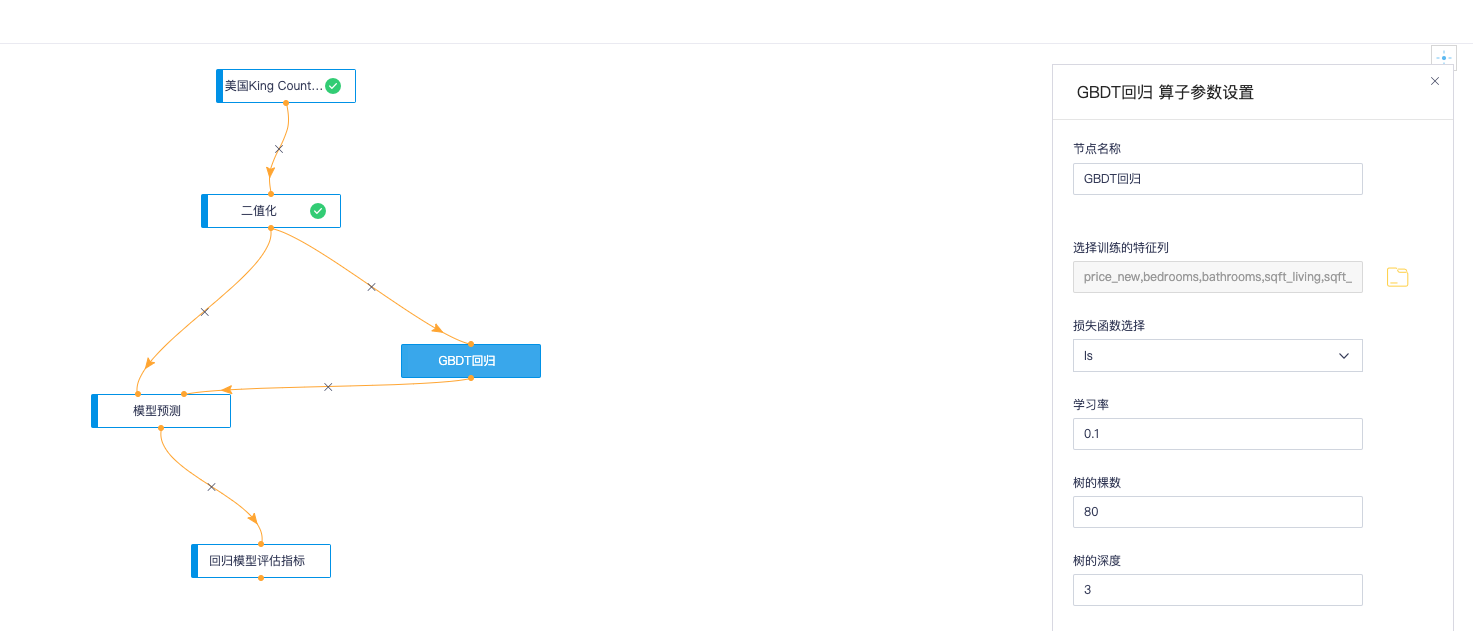 模型类算子需要指定特征列与标签列,需要先运行模型类算子以上的算子,才能获得对应的特征列和标签列。
算子简介
以信贷审批项目为说明案例,在左侧算子区中分为数据IO、预处理、机器学习模型、样本数据、特征工程和模型评估等6种算子类型。所有算子均具有右击和双击操作。
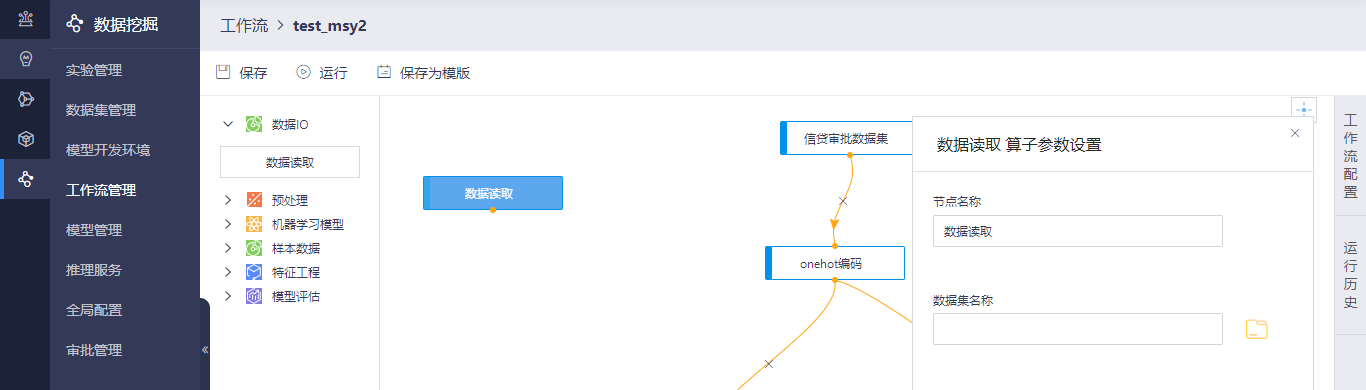
数据IO:包含数据读取算子,右击算子可以重命名、删除和复制算子,查看日志,运行算子。双击算子可以设置算子参数,如节点名称和数据集名称。算子支持版本为Spark单机和集群版。
模型类算子需要指定特征列与标签列,需要先运行模型类算子以上的算子,才能获得对应的特征列和标签列。
算子简介
以信贷审批项目为说明案例,在左侧算子区中分为数据IO、预处理、机器学习模型、样本数据、特征工程和模型评估等6种算子类型。所有算子均具有右击和双击操作。
数据IO:包含数据读取算子,右击算子可以重命名、删除和复制算子,查看日志,运行算子。双击算子可以设置算子参数,如节点名称和数据集名称。算子支持版本为Spark单机和集群版。
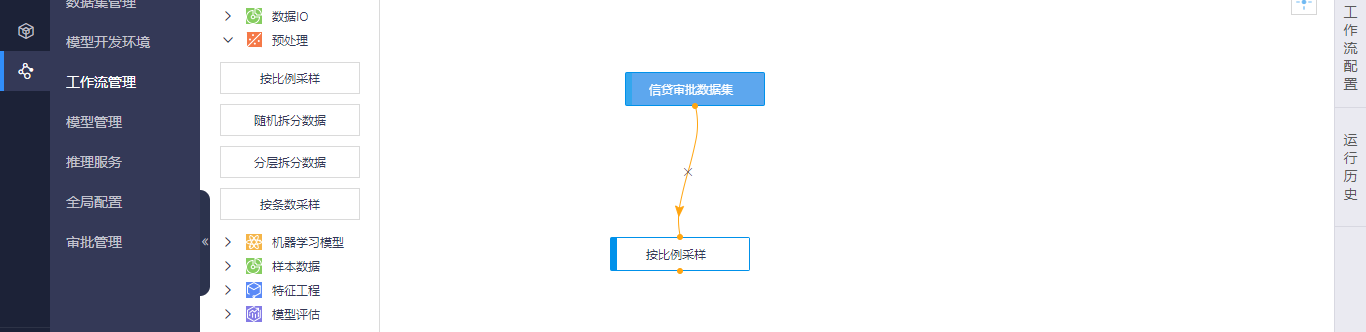
 数据预处理:包括按比例采样、随机拆分数据、分层拆分数据和按条数采样4种算子类型。其中右击每个算子均支持重命名、删除、复制、运行算子操作,同时支持查看日志和支持小数据量运行操作,其中小数据量运行具体分为全部运行、运行到此和运行此算子操作。算子输入和输出数据格式均为DataFrame。
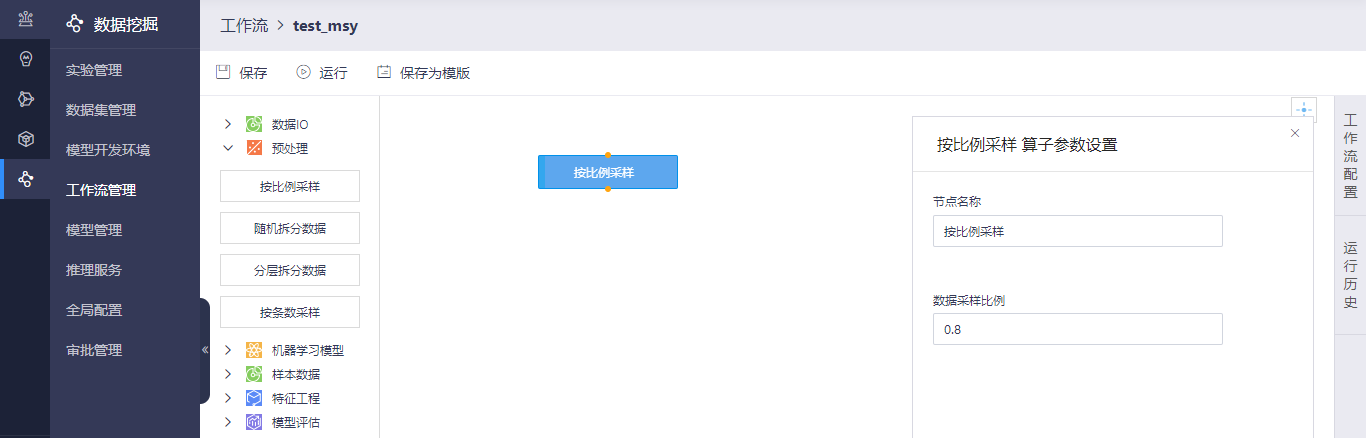
其中按比例采样算子页面支持设置节点参数操作,您可以输入数据集采样比例。
数据预处理:包括按比例采样、随机拆分数据、分层拆分数据和按条数采样4种算子类型。其中右击每个算子均支持重命名、删除、复制、运行算子操作,同时支持查看日志和支持小数据量运行操作,其中小数据量运行具体分为全部运行、运行到此和运行此算子操作。算子输入和输出数据格式均为DataFrame。
其中按比例采样算子页面支持设置节点参数操作,您可以输入数据集采样比例。
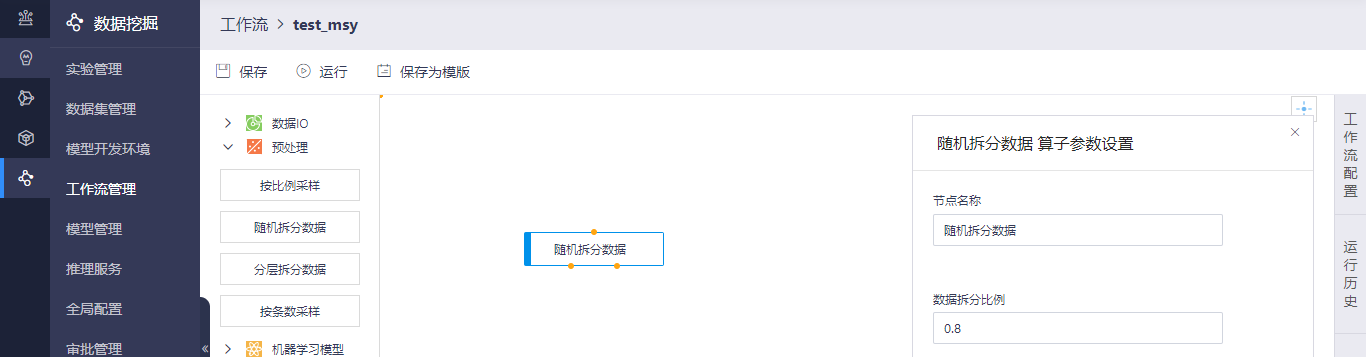
 随机拆分数据算子页面支持设置算子参数操作,您可以输入数据拆分比例。
随机拆分数据算子页面支持设置算子参数操作,您可以输入数据拆分比例。
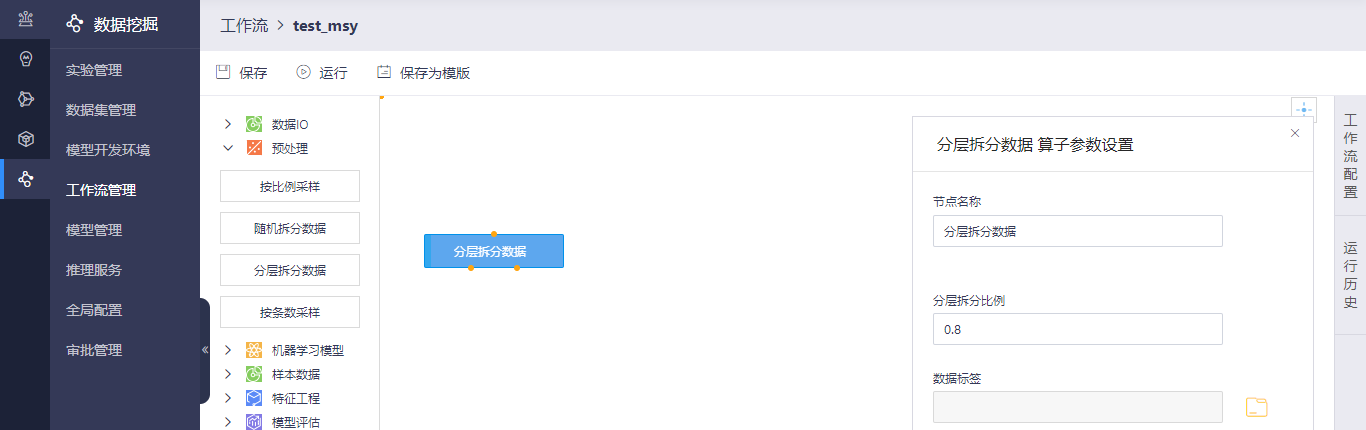
 分层拆分数据算子页面支持设置算子参数操作,您可以输入分层拆分比例和数据标签等信息。
分层拆分数据算子页面支持设置算子参数操作,您可以输入分层拆分比例和数据标签等信息。
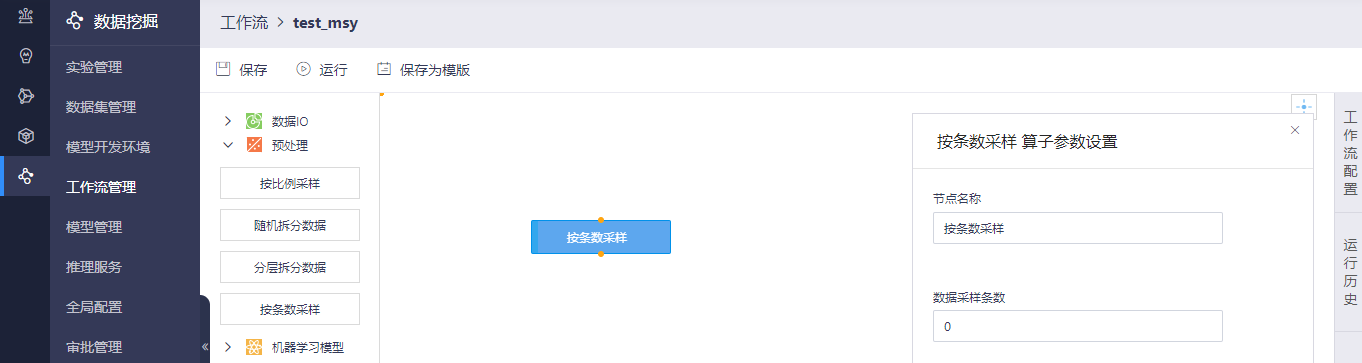
 按条数采样算子页面支持设置算子参数操作,您可以输入数据采样条数。
按条数采样算子页面支持设置算子参数操作,您可以输入数据采样条数。
 机器学习模型:包含GBDT回归、xgboost二分类、K均值聚类和GBDT二分类四种算子类型。右击算子均支持重命名、删除、复制、运行算子操作,同时支持查看日志和支持小数据量运行操作,其中小数据量运行具体分为全部运行、运行到此和运行此算子操作。
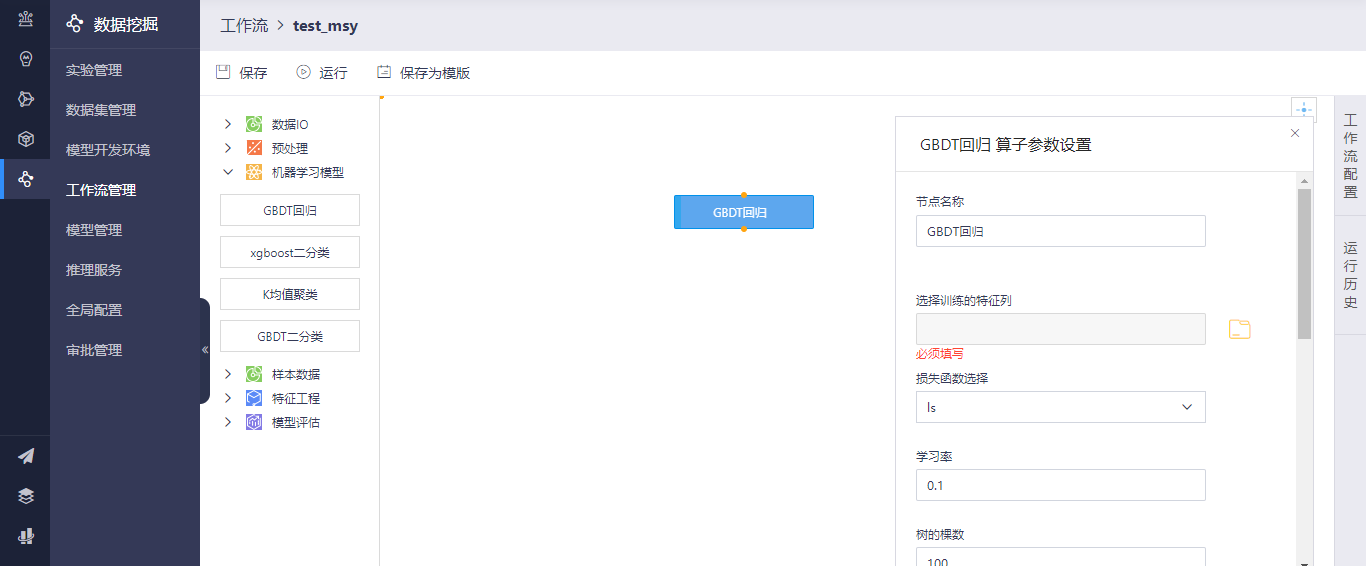
其中GBDT回归算子支持解决回归任务,双击算子支持设置算子参数,参数涉及选择特征列、选择损失函数、学习率设置、数的颗数、树的深度、节点分割时方法、分割时的最小样本数、叶子节点最小样本数、采样率、最大特征所占比例和选择模型的标签。节点分割时的方法分为friedman_mse、mse和mae三种方法。
机器学习模型:包含GBDT回归、xgboost二分类、K均值聚类和GBDT二分类四种算子类型。右击算子均支持重命名、删除、复制、运行算子操作,同时支持查看日志和支持小数据量运行操作,其中小数据量运行具体分为全部运行、运行到此和运行此算子操作。
其中GBDT回归算子支持解决回归任务,双击算子支持设置算子参数,参数涉及选择特征列、选择损失函数、学习率设置、数的颗数、树的深度、节点分割时方法、分割时的最小样本数、叶子节点最小样本数、采样率、最大特征所占比例和选择模型的标签。节点分割时的方法分为friedman_mse、mse和mae三种方法。
 参数说明:
参数说明:
| 参数 | 说明 | 默认值 |
|---|---|---|
| 损失函数 | 度量模型输出的预测值,与实际值之间的差距的一种方式。损失函数分为ls、lad、huber和quantile四种。 | ls函数 |
| 节点分割时的方法 | 分割节点,方法分为friedman_mse、mse和mae | friedman_mse |
| 参数 | 说明 | 默认值 |
|---|---|---|
| 初始中心点选择 | 选择初始的中心点方法,支持k-means++和random方法 | k-means++ |
| 参数 | 说明 | 默认值 |
|---|---|---|
| 损失函数 | 度量模型输出的预测值,与实际值之间的差距的一种方式。支持deviance和exponential | deviance |
| 分割时方法选择 | 类别分割时的方法,支持friedman_mse、mse、mae | friedman_mse |